


圖1:識別物體步驟

圖2:物體識別的廣泛應用
對於傳統的神經網路分割方法,有着參數過於龐大,極大的減慢了處理的速度;除此之外,當卷積步長大於一的時候,會降低圖像的分辨率,從而損失很多重要的信息,剩餘的信息又會經過池化層,加劇了對於信息的丟失,這對於我們的分割任務都是非常不利的。而早期的deeplab算法,由於沒有解碼(decoder)模塊,由於存在一些特徵擴展,會使得在encoder的時候變慢;同樣因為沒有解碼器,無法和原始的圖像信息進行連接,會造成一些細節難以恢復。為了解決這些問題,在deeplabv3中添加了一個簡單而有效的解碼器,形成了編碼-解碼的結構。它有如下好處:1.首先保證了圖像分辨率不會因為池化而造成損失。2.加入ASPP大大降低了參數並增加了感受野。不再滿足於原有encoder出來的結果,而是通過加入解碼器對原來的結果進行優化。總結來說就是克服了傳統標準卷積的缺點,對物體的邊界進行更快更有效的恢復。
我們需要使用空洞卷積和編解碼技術更快更準確的完成語言分割任務,需要介紹deeplabv3+技術,下面介紹它的framework。首先我們需要輸入一張圖片,它的分辨率是512*512的,擁有RBG三個通道,也就是說是一張彩色圖像,然後我們模型的訓練和優化,第一步是將其輸入到Resnet中,關於Resnet的部分我們接下來會專門提到,我們把Resnet的結果進行ASPP處理。在ASPP中,我們選用不同的Rate進行Convlution,它們分別是1*1和3*3的conv,其中3*3又分為6,12,18三種不同rate,在分別計算出結果後,我們可以獲得5個32*32*256的結果,我們把它們進行concatenate,隨後我們將結果再經歷一個1*1的Filer,目的是為了降低參數,由此我們通過整個encoder獲得了一個32*32*256的局部特徵。總結起來就是說Encoder就是原來的DeepLabv3,注意點有2點:輸入尺寸與輸出尺寸比(output stride = 16),最後一個stage的膨脹率rate為2。Atrous Spatial Pyramid Pooling module(ASPP)有四個不同的rate,額外一個全局平均池化。這裡我們需要額外介紹depthwise convolution(P5右上)是在每個通道上獨自的進行空間卷積,pointwise convolution是利用1×1卷積核組合前面depthwise convolution得到的特徵。為什麼說要用它呢?因為它能夠保持性能的同時大大減少計算量,假若輸入2通道的特徵,輸出3通道特徵,卷積核大小為3×3正常的卷積參數量為2x(3×3)x3=54,而深度可分離卷積參數量為2x3x3 + 2x1x1x3 =24其中第一部分為depthwise convolution(2x3x3),第二部分為pointwise convolution(2x1x1x3)。我們再來關注decoder的情況,先把encoder的結果上採樣4倍,然後與resnet中下採樣前的Conv2特徵concat一起,注意融合低層次信息前,先進行1×1的卷積,目的是降通道(例如有512個通道,而encoder結果只有256個通道)。再進行3×3的卷積,最後上採樣4倍得到最終結果。這樣我們在encoder階段獲得了局部特徵,在decoder階段融合了全局特徵,可以獲得比較好的結果。
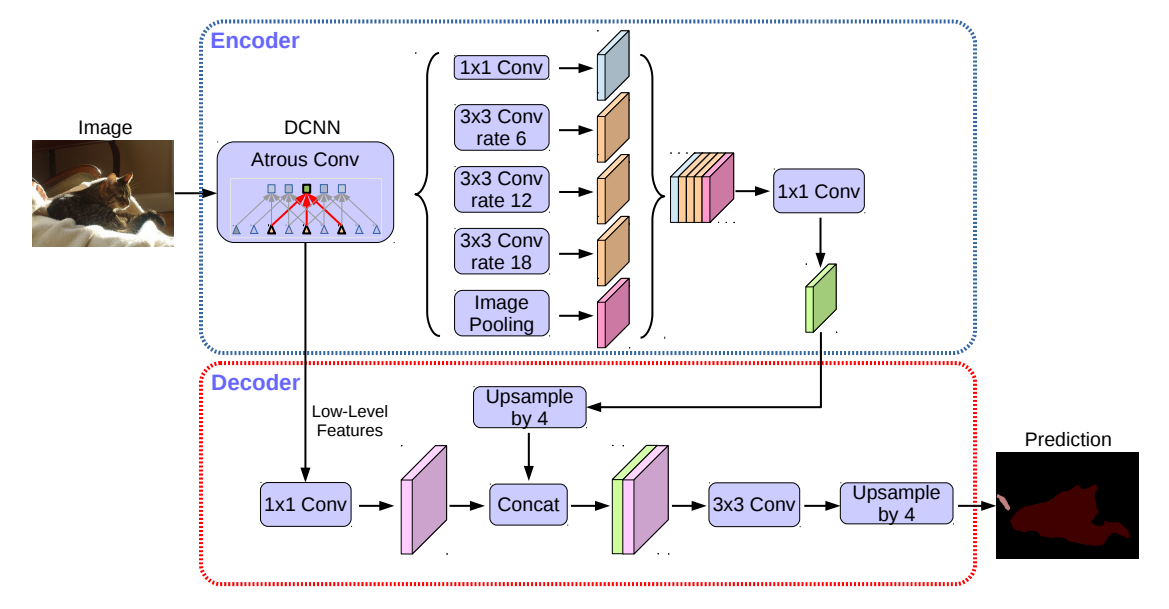
圖3:deeplabv3+的架構
我們在獲取不同尺寸的資訊時,通常會有幾種不同的方法,1)首先是圖像金字塔,小的卷積去捕捉遠程上下文,而大的卷積用來保留詳細的信息,我們通過多個不同尺度的卷積獲得不同層次的信息,再將它們融合,但這樣做會耗費大量的gpu資源,基本在理論上的有效而實際上是不存在的2)第二個是編碼器-解碼器結構:此模型由兩部分組成:(a)編碼器,其中特徵圖的空間尺寸逐漸減小,因此在較深的編碼器輸出中更容易捕獲更長的範圍信息;以及(b)解碼器,其中物體的細節和空間尺寸逐漸得到恢復。3)更深層次的空洞卷積:此模型包含各種不同卷積的分層模塊,以對遠程上下文進行編碼。4)空間金字塔池:該模型採用空間金字塔池捕獲多個範圍的上下文。從DeepLabv2開始提出了空間金字塔池化(ASPP),其中具有不同rate的並行卷積層捕獲多尺度信息。
deeplabv3+實現了deeplabv3的基本內容,包括編碼-解碼結構中的編碼器,除此之外,使用了編碼器來包含豐富的語義訊息,同時一個簡單而有效的解碼器來恢復物體邊界的資訊,編碼層允許我們藉助ASPP萃取不同尺寸的信息。其中我們介紹的深度可分離卷積是一種有效的操作,用來減少計算成本和參數量,並保持良好的性能。
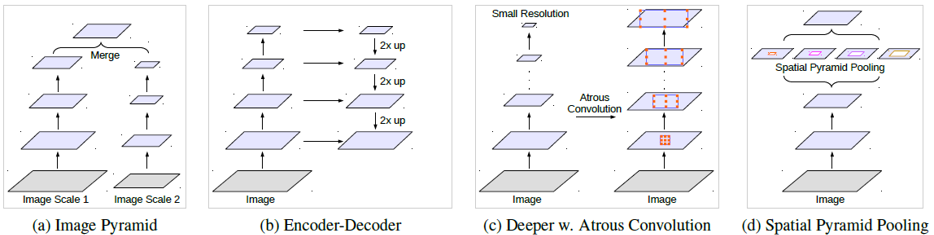
圖4:對於捕捉不同尺度的上下文,我們可以使用不同的架構。
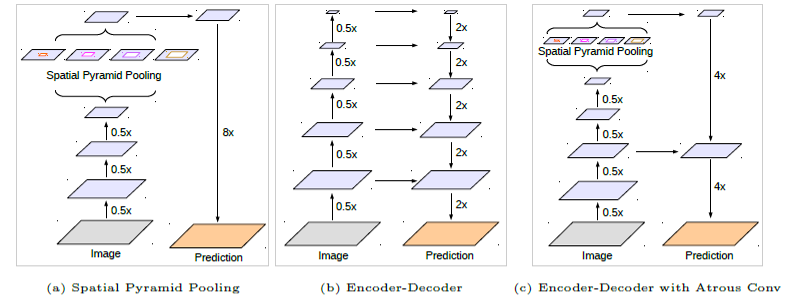
圖5:多種不同的手段幫助我們提升deeplabV3的結果
我們對幾個具體的問題進行討論,首先是DACNN,它的定義是基於ResNet的DeepLabv3,它在第1,2,3的block中的下採樣使用卷積步長為2的3*3的max pooling實現的,block4是對5,6,7的複製,而ASPP則應用在第4,5,6層。包括不同類的輸出分割圖,請參閱:用於語義分割的學習反卷積網絡。在訓練的過程中,我們的batch size可以是4,8,12,16的任何值,我們的初始learning rate為0.007,而每運行三萬次進行一次learning rate的更新,在另外一組試驗中,我們將初始的learning rate調節到0.001,同樣也是三萬次進行一次更新。
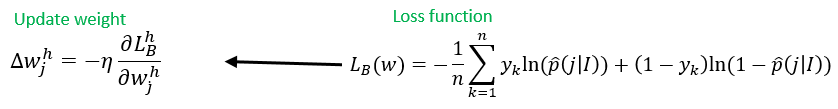
圖5:Learning rate

圖6:Learning rate的更新
接下來介紹的是空洞可分離卷積,它分為兩個部分,空洞深度卷積,類似從空間上去解決問題,另外是從點的角度去考慮問題,我們需要把一個9*9*3的下採樣成1*1*1的卷積,我們先使用一個3*3*1的過濾器進行下採樣,得到1*1*3的卷積,隨後再次使用1*1*3的卷積得到一個1*1*1的下採樣結果,在整個下採樣的過程中,我們結合了空洞卷積的技術,代替我們原有的第一步,也就是Depthwise Conv。在我們的實作中也將深度可分離卷積分為深度卷積和點卷積,深度卷積可以對每個層都起到作用,點卷積是將不同層的內容綜合起來。我們使用卷積步長為2的卷積去代替第一步的深度卷積,希望擴大感受野。
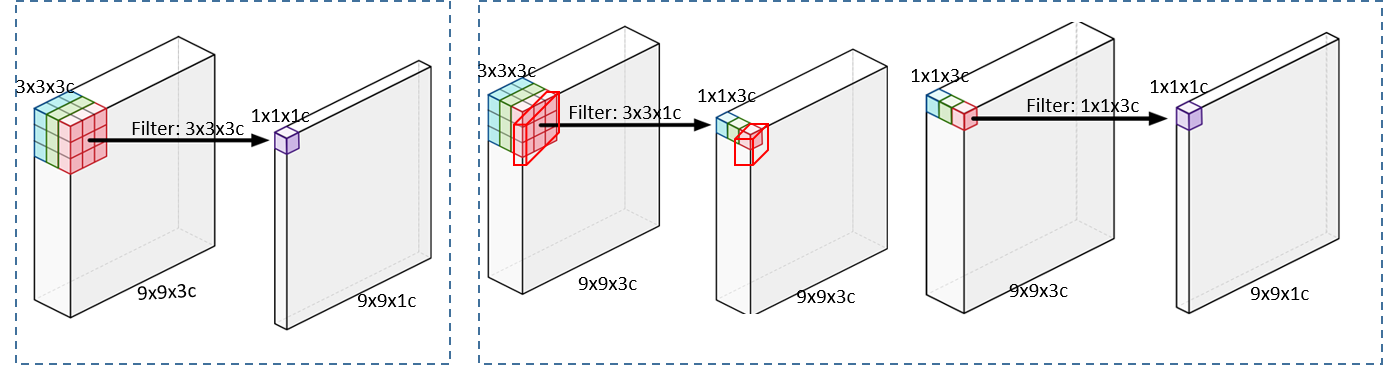
圖7:空洞可分離卷積
由於我們一開始使用了ResNet,在這裡我們對它做一下簡要介紹,一般來說,隨着神經網路層數的增加,結果會有一定的提升,然而過多的層也會造成梯度下降,一些局部細節被丟失,為了合理解決這個問題,resnet提出跨過一些層,而將原始信息和結果進行運算合併,這種思想在現在很多主流的神經網絡架構上都有應用,Resnet就是使用這種方法且經過了101層的conv,它每一個節點的輸入和輸出都是相同,即28*28*256。當這個尺寸的輸入進來時,我們使用64個filter對它進行投影,得到的結果再經過3*3*64.最後得出結果。
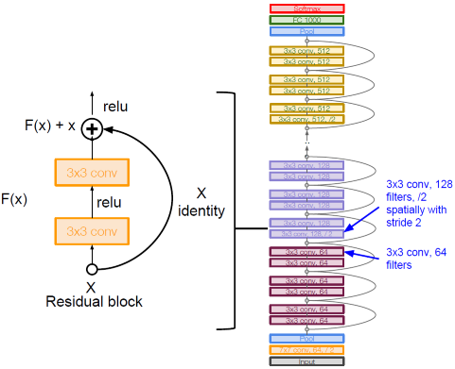
圖8:Resnet架構