

目录 一.研究动机...........................................................2 二.数据源介绍.......................................................3 三.系统介面和基本功能...............................................4 3.1主介面.......................................................4 3.2历史资料查询.................................................5 3.3预警与动作...................................................6 3.4资讯与救援...................................................7 3.5账号与数据...................................................8 3.6网页发布.....................................................9 3.7即时网页显示................................................10 四.技术细节........................................................11 4.1原始文件制作器..............................................11 4.2处理器......................................................12 4.3错误处理记录器..............................................15 4.4单测站数据文件..............................................15 4.5前端用户文件交互组..........................................15 4.6用户动作捕捉................................................15 4.7用户主介面..................................................16 4.8数据点抽象技术..............................................16 4.9图表绘制技术................................................16 4.10设置修改与提交.............................................17 4.11垃圾回收...................................................17 4.12测站资料搜寻...............................................17 4.13资料库技术.................................................18 4.14模型实践...................................................18 4.15灾害特色短信...............................................19 五.遇到的困难......................................................20 六.未来展望和改进空间..............................................22 八.致谢............................................................23 九.总结与心得......................................................24
通常认为,地震可以制造广泛的伤害,而由于人类还没有完全了解地壳内部的活动和构造,所以地震的预测是非常困难的,即使以目前的科学水准,仍然难以对其发生原因,机制和预测方法进行系统的认知和总结。但是在地震发生之后,我们可以对其进行预警,利用地震波到达地面的时间差来指导地面上的人进行避难工作。现有系统已经比较完善,我们可以收到手机短信或者推送,但是由于是针对一个区域的群发机制,很多人在地震发生时不知所措,不知道在哪里避难,食物和水源在哪里,这造成了潜在的危险。另外,在地震发生后,我们往往被动寻找伤者,而没有对区域人员的一个全局把握,到底有多少人,有没有联系电话等等。同时对于研究人员,也缺乏一个可以即时观察地震数据,或者回溯之前的地震情况的方法。我们需要一个系统,来帮助我们解决上述我们提到的问题。
我们的数据源来自中央研究院分布在全台湾的三百余个测站,其主要使用三联科技股份有限公司的Palert地震 P 波警报仪。每个测站每秒至少会产生1200个原始数据,通过socket通讯即时传输到台湾科大伺服器。我们的软体即时读取这些资讯来进行分析和预警工作。由于每秒传递的数据量大,对软体的即时性和可靠性提出了非常大的考验。
我们已经提到,测站每秒钟会传递1200个原始资料,但是我们主要用到的是其中的一部分,它包含了此测站在一秒钟在空间XYZ中的移动情况。下表提供了一些资料每个short的定义。但值得注意的,这已经是处理完成的样式了,实际的接收数据,我们需要用两个byte来拼合成一个short,这一点在此不多做赘述。
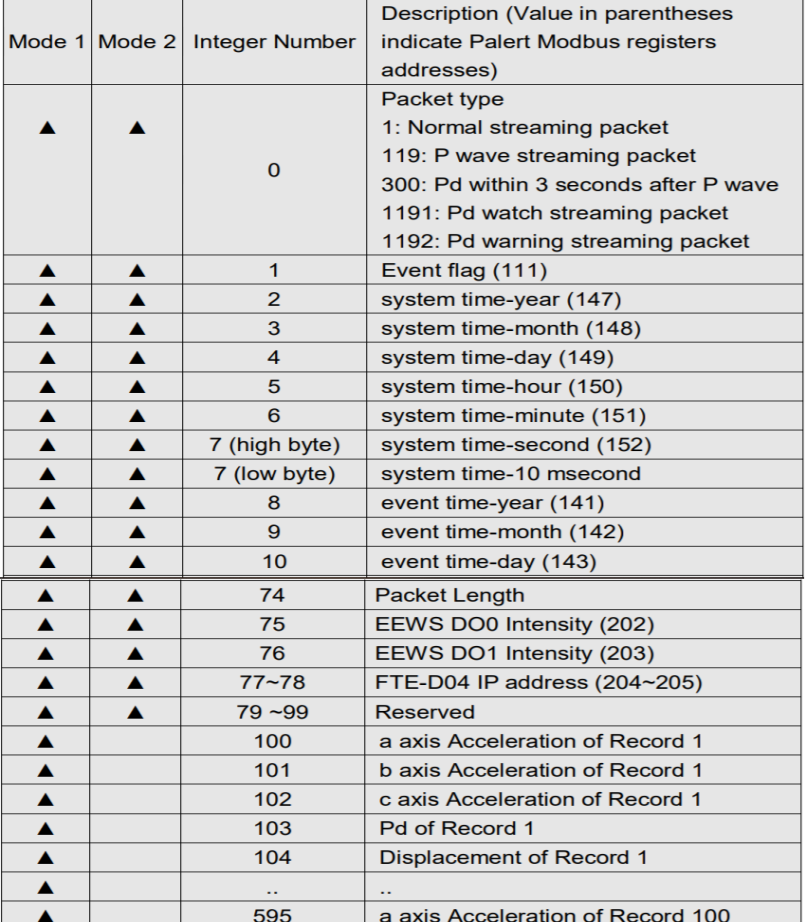
3.1主介面
这是我们的主介面,也是我们最开始看到的操作面板。
首先我们需要选择一个区域,点击右侧的“获取”按钮,可以获得该区域的所有测站。我们可以对这些测站进行分别查看,点击“送出查询”,可以看到在下方显示测站的编号,位置和备注,此时,右侧并没有地震图表的显示,因为我们还需要指定我们所查看的坐标轴。如果把探测器看作一个放在空间中心的物体,则它会有三种运动方向,平面上的前后和高度的上下,这样构成了一个三维坐标系,我们可以对每个维度的震动进行分别查看。这样的图形几乎是实时的,理论误差在30秒以内,而由我们系统生成的网页版本,其误差可以在10秒以下。虽然我们的系统在设计之初有着较高的时间敏感性,但直到实作结束,时间误差依然有10秒左右,其中原因会在之后讨论。
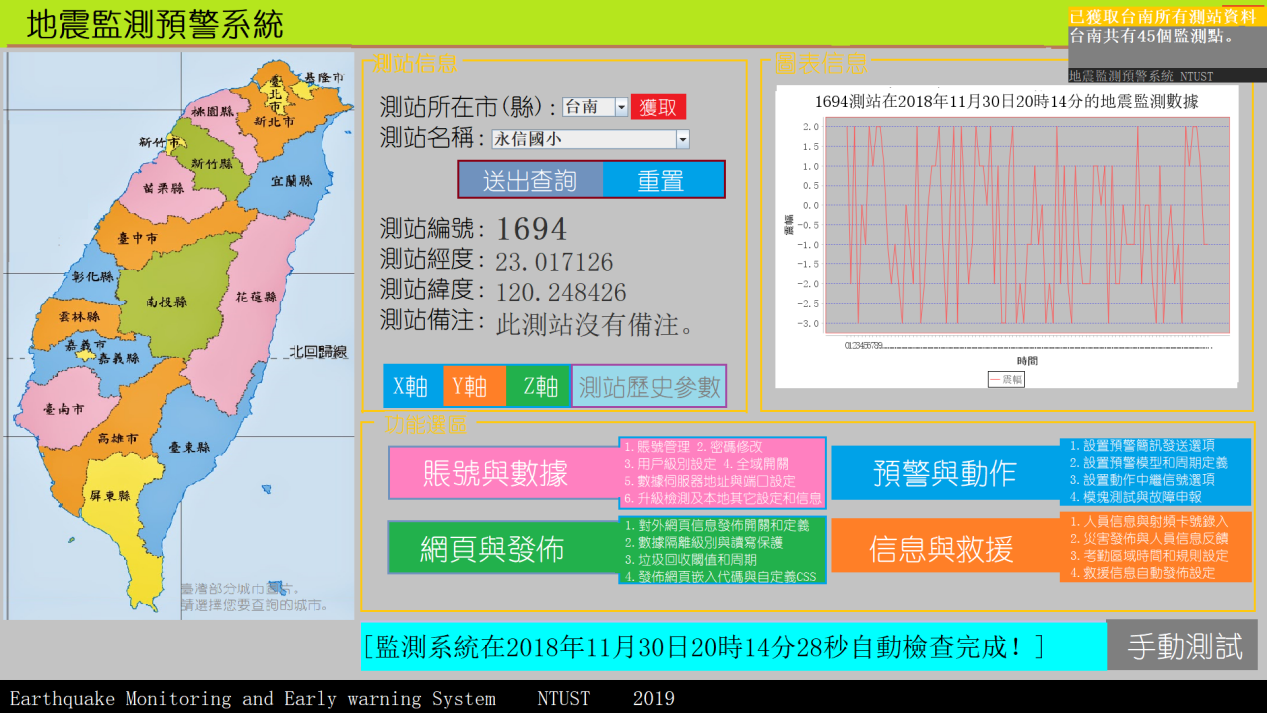
3.2历史资料查询
当然我们还可以获得任意时间和任意测站的参数情况。我们可以使用系统提供的历史功能,帮我们查看已经发生的地震行为,但是由于我们的数据量非常大,对此我们引入了垃圾回收概念。有可能我们查询的测站在没有保护的情况下资料已经被删除,所以我们要保障数据的存在性。
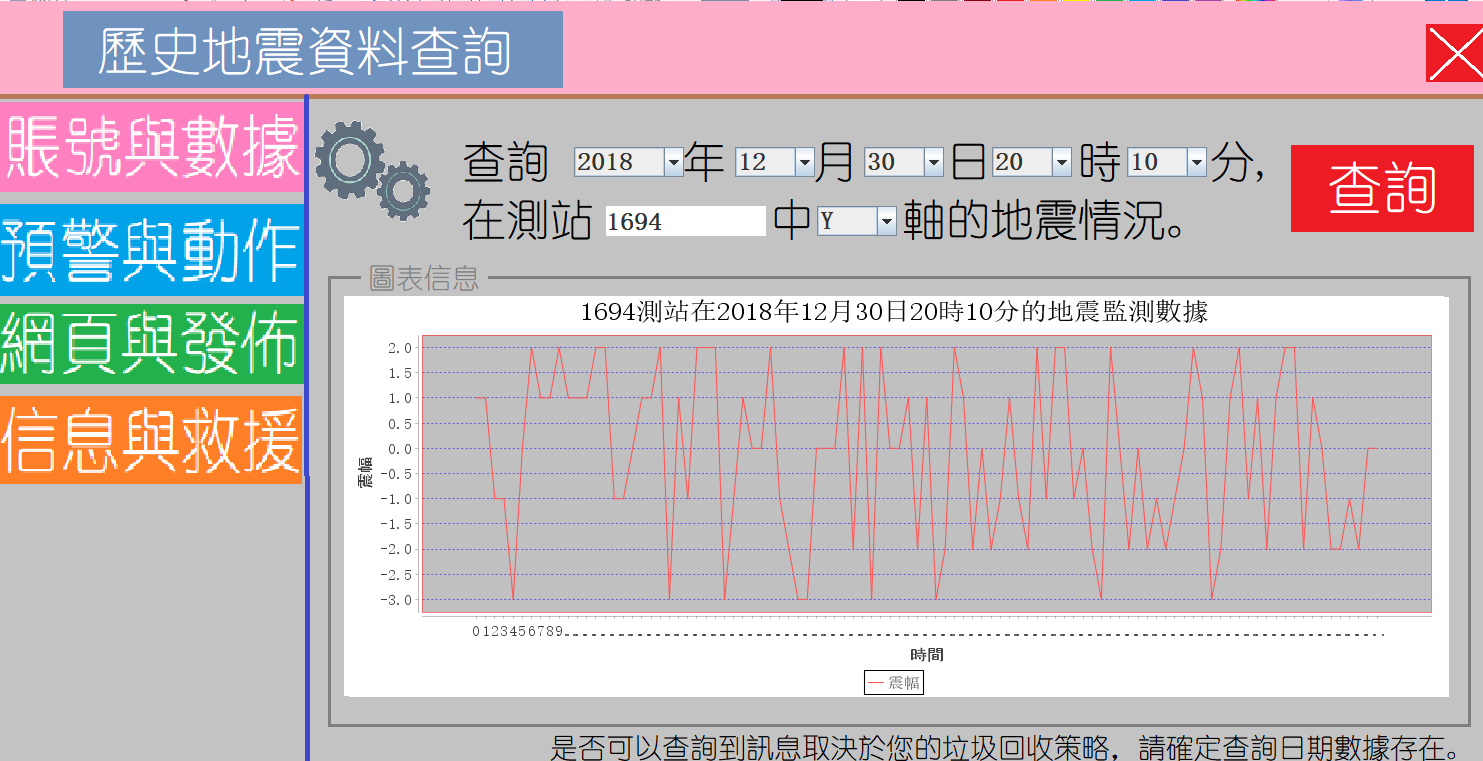
3.3预警与动作
我们允许用户自行定义模型,即定义什么情况是发生了地震,以及地震发生后的动作。
首先是单点模式,它只能专注一个测站,去看它是否产生了地震信号,但也正是于此,它的效率非常高,几乎不会对处理数据造成影响。
其次是多点复杂模式,我们允许用户对多个测站进行监控,他们用逗号分隔,和单一测站检测的机制相同,所有测站一旦发生用户定义的情况,就会出发地震报警。所谓报警,我们主要通过短信通知所有在此区域的用户,这个在之后会详细讨论。
我们还设想了高级的复杂模型,主要对所有数据执行区域聚合和长短周期定义,使得他们具备时间上的关联性。但是由于实际测试中,这样会严重影响我们数据的处理速度,所以在最终版本的软体中,我们暂时去掉了这个功能。
接下来是动作中继,也就是我们检测到发生了地震,也给用户发送了短信,可是然后呢,于是我们支持一些基本的功能,比如可以关机保护系统,也可以通过发送数据包或写入为文件的方式,给其他系统通报地震信号。我们还允许用户自定义任意的执行语句。这些语句只要是符合命令提示字元,都可以被准确的执行。最后,我们提供了短信的开关,可以自由的打开短信发送的管道。
但是,我们如何通知用户来告知地震呢,首先需要介绍我们的帐号功能。
3.4资讯与救援
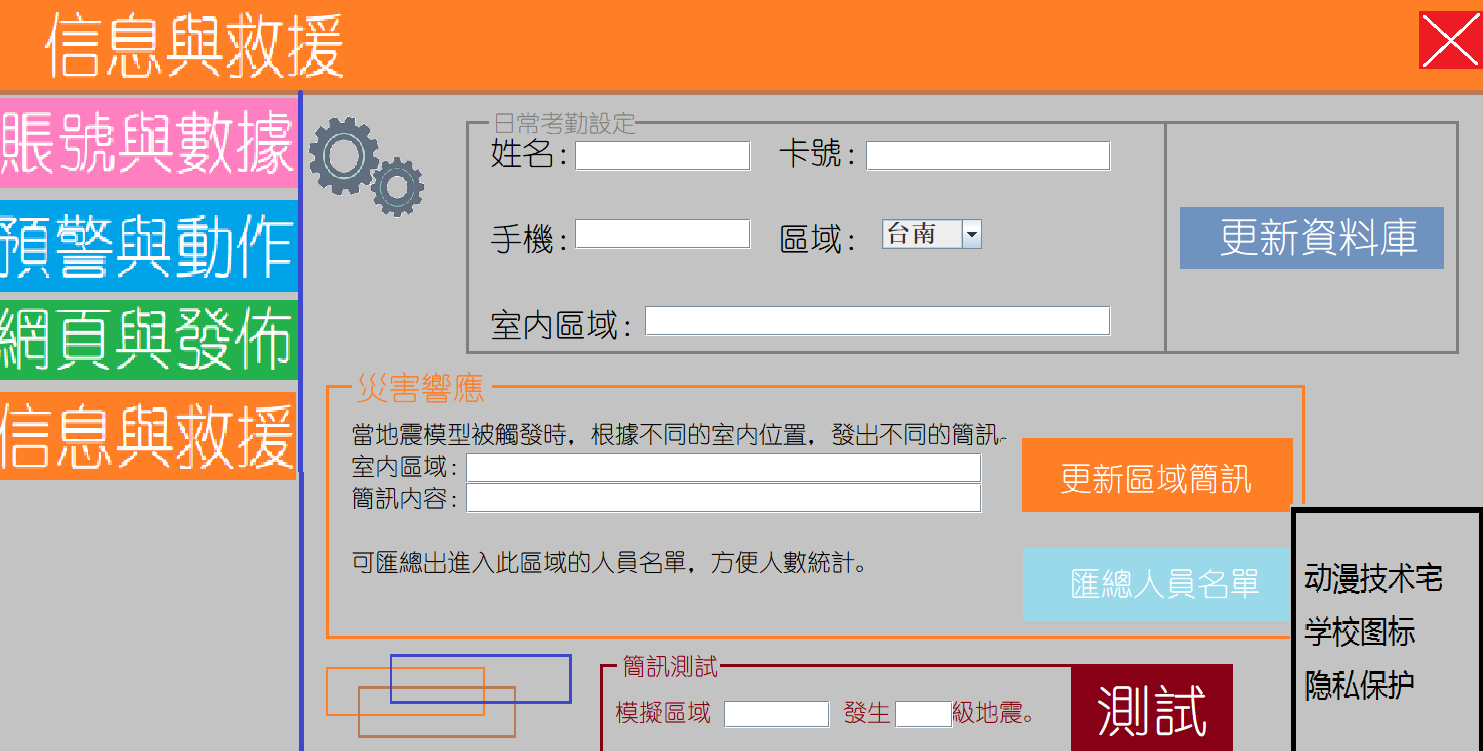
我们允许一个新的用户注册,用户需要提供他的姓名手机和所在区域,同样也要提供室内区域,我们的室内区域将会在接下来进行定义,所谓室内区域我们会单独定义他的报警资讯,比如用户在一楼,我们会指导他找到出口,当用户在高楼层时,我们会告诉他如何避难以及找到食物和水。同时,我们也可以汇总出每个室内区域的全部人员名单和他们的联系方式,对接下来的救援工作有着比较大的协助。最后我们可以让用户进行测试来尝试对区域内的用户发送提示短信。
3.5帐号与数据
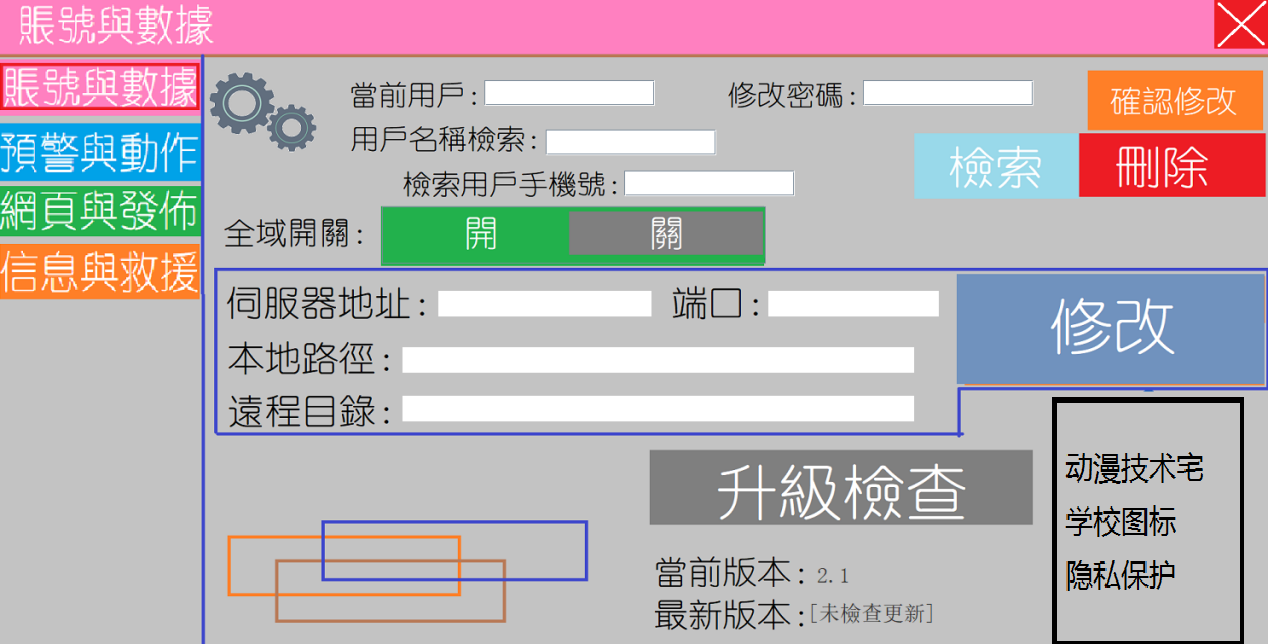
对于4中定义的用户,我们可以对其进行修改密码,同时通过姓名和手机号码,我们也可以对用户的讯息进行查找,同样的对于接收伺服器和端口以及本地路径,也可以由用户自定义,方便有迁移需求的用户。
3.6网页与发布
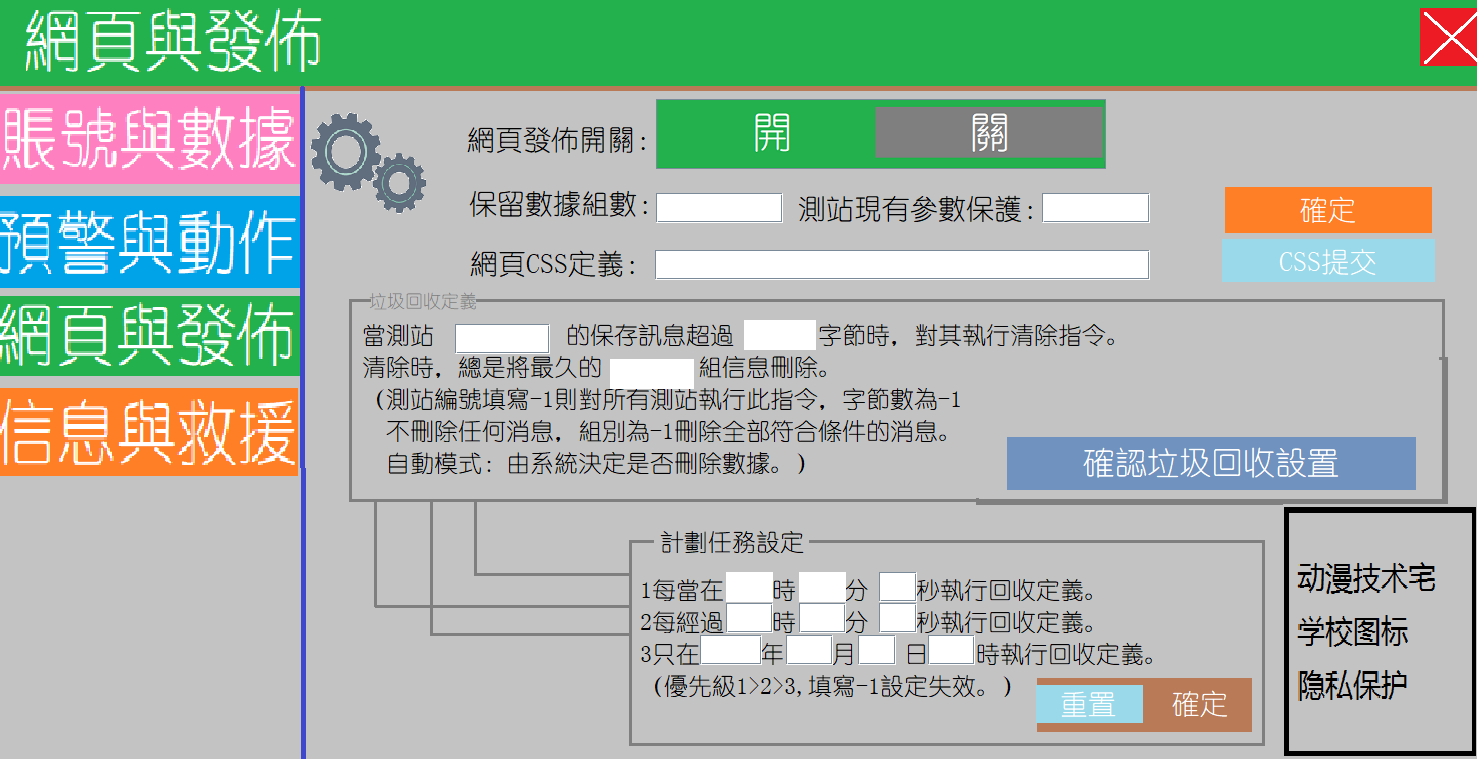
我们可以在帐号与发表中定义网页的开关,即是否允许用户查看即时的地震情况,我们也对一些CSS定义进行扩展,方便前端网页的人员进行引用。我们定义了三种垃圾回收的方式1.第一种时定时回收,设定一个时间,然后在这个时间回收它。2.其次是每隔多久进行一次回收的定义。最后是只进行一次的回收方式。用户可以根据自己的情况对应回收模式,但是由于我们会产生大量数据,用户需要保证磁片空间的剩余量。
3.7即时网页显示
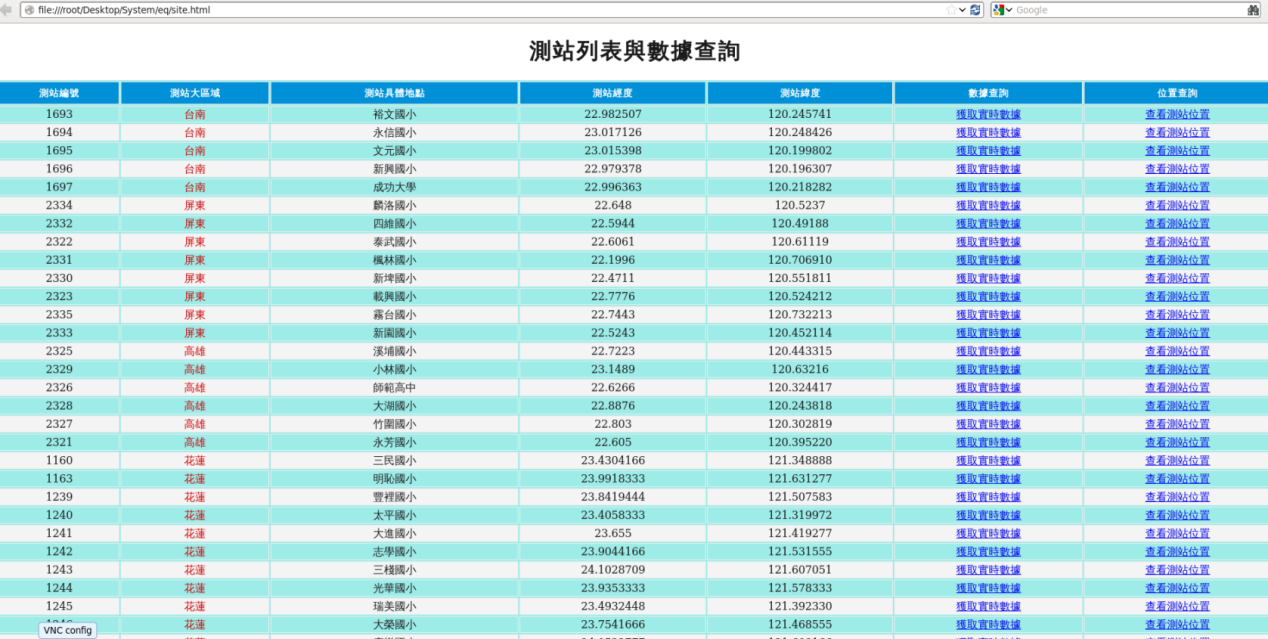
首先我们对本软体中所有遇到的技术进行逐个解析:
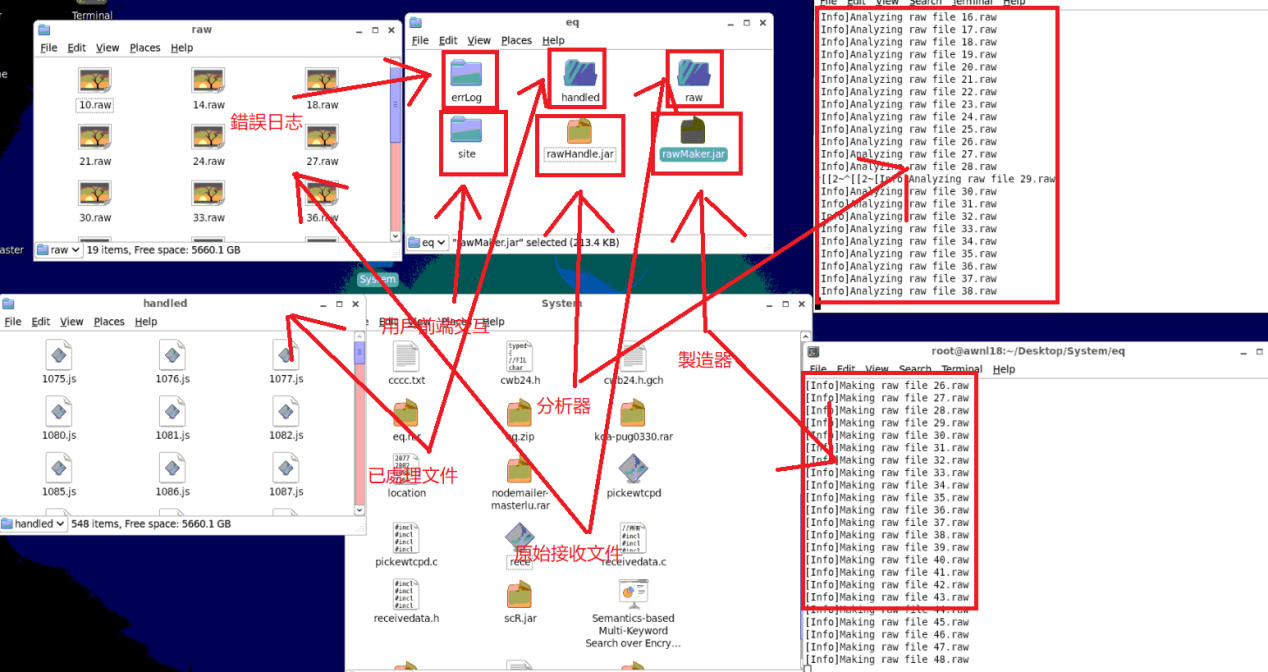
我们先定义几个基本模组
4.1原始文件制作器(RawMaker.jar)
主要用来接收来自socket中的讯息,并将它解码,分割写入磁碟中,它是始终的无条件的运行的,不受程式其他模块的干扰,也不要求有对齐或其他解析功能。它生成后缀名为raw的文件并保存在raw文件夹下。
我们先定义一个位元组转换方法,用于将两个byte 拼接成一个short
public static short byteTransform(byte a,byte b) {
return (short) ((a << 8)| (0x00FF & b));}
另外,容器也是必不可少的,用来作为buffer保存我们的数据
public static byte[] itb(InputStream in) throws IOException{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] data = new byte[1204];
int count = -1;
int MaxWaitTimes=0;
while(((count = in.read(data,0,1204)) != -1)&&MaxWaitTimes<1) {
outStream.write(data, 0, count);
MaxWaitTimes++;}
data = null;
return outStream.toByteArray();
}
}
记录单个文件中的short数据数目,把它的初始值设为350*1202,是希望它第一次就能进入初始化文件的操作流程,它会在初始化后重新变为0
int rawRecCounter=350*1202;
全局计数器,记录当前的档案名称,有控制文件回圈记录的功能
int rawRecGlobalCounter=-1;
BufferedWriter out = null;
开启Socket管道
Socket s = new Socket(“140.110.141.23”,23000);
InputStream is = s.getInputStream();
我们的接收工作原则上不会停止,所以是while让它永远执行
while(true){
检测是否要建立一个新的文件,如果计数器表明已经产生了所有测站1秒的数据则新建立一个文件。
if(rawRecCounter>=350*1202) {
一个新的文件建立了,我们把计数器清零。
rawRecCounter=0;
如果全局计数器大于等于100,则让它为0,覆蓋100秒前的数据文件。
if(rawRecGlobalCounter>=99+1) {rawRecGlobalCounter=0;}else{System.out.println(“[Info]Making raw file “+(rawRecGlobalCounter+1)+”.raw”);
新建或覆蓋全局计数器指定的文件
rawRecGlobalCounter++;}
新建文件对象,它等于全局计数器的名称
File writename = new File(“raw”+File.separator+rawRecGlobalCounter+”.raw”);
新建文件
writename.createNewFile();
获取输出缓存
out = new BufferedWriter(new FileWriter(writename));}
将is流中的数据一行一行传入byte数组,方便之后的分析。
byte[] bytes = itb(is);
我们现在对单行byte数据进行处理
for(int i=0;i<bytes.length;i=i+2) {
把后面的byte和前面的byte粘贴,组成一个short
out.write(byteTransform(bytes[i+1],bytes[i])+” “);
当前文件记录的short数自增
rawRecCounter++;}
刷新缓存
out.flush();}}
至此,我们完成对于原始scoket数据包到原始文件的转换过程。
4.2处理器(Handle.jar)
主要用来解析制作器生成的文件,将混杂着预警资讯的所有测站(单秒)原始文件,解析分割到各自测站的文件资讯中,它可以创建并修改文件,并有一定的客观纠错功能(覆蓋写入)。同时它也控制着单个测站保存数据的最大值,避免磁盘空间溢出。
处理器承载这用户网页的显示和我们软体内部的显示,由于提供给用户的数据没有经过过滤和处理,所以速度会比较快。在这里,我们会忽略软体内部的文件处理方法,只讲述给用户流览器的呈现方法,因为方法是及其类似,而网页处理的过程相对简单。
首先我们需要一个文件处理计数器,用于标识我们处理到第几个文件,和制作器配合,初始数值范围是0到9999,当达到9999时,自动变为0,防止文件过多积压磁片和int形变量溢出。
int rawHandleController=0;
我们需要不停的处理制作器的资讯,所以是无限回圈
while(true) {
System.out.println(“[Info]Analyzing raw file “+rawHandleController+”.raw”);
生成一个文件对象,它将在之后读取制作器的预处理文件,使用separator方法是为了相容系统路径在Linux的使用。
File file = new File(“raw”+File.separator+rawHandleController+”.raw”);
检查文件存在性,通过与else配合,如果文件不存在,我们会让系统等待两秒之后再做检查,通常文件不存在是由于处理器先于制作器启动,或制作器在写入数据时发生延缓,这类情况通常较少出现
if(file.exists()) {
承载容器,接纳制作器生成的全部文本内容,供之后分析。
int[] a = getLineFromTxt(file,” “);
预先声明3个int形数组,他们将在之后承载单个文件
单个测站的xyz轴讯息。每个轴有100个资料。
int xData[] =new int[100];int yData[] =new int[100];int zData[] =new int[100];
这里记录的时测站编号,因为我们是通过之后的长度和时间来定位数据的,这时候测站编号已经被解析,我们需要一个变数来保存测站的编号,给以后使用。
int site=0;
遍历文件容器中的每一个数据,1200为安全边界,防止在解析到测站编号和时间后测站资讯不完整。
for(int i = 0; i< a.length-1200; i++){
如果我们解析到一个1200的数据且它的后面跟了一个正确的年份,我们则认为它是一个测站资讯的开始。我们可以再细化时间检查来提高它的准确度,但根据实际检测情况,这样的检查已经够用了,目前没有差错报告。
if(a[i]==1200&&a[i+3]==2018&&i<a.length-1200) {
回溯一个数据,将其记录在变数site中。
site=a[i-1];
这一组数据记录和控制写入在单个测站单轴的数组位置。
int xCounter=0;int yCounter=0;int zCounter=0;
根据具体要求,我们解析全文数据的102位(正文数据的100位),到数据包结束
for(int j=102;j<=601;j++) {
其中,每组数据(5个)有两个是我们不需要的,我们把它舍弃,只留下需要的部分
if(j%5==2) {xData[xCounter]=a[i+j];xCounter++;}if(j%5==3) {yData[yCounter]=a[i+j];yCounter++;}
if(j%5==4) {zData[zCounter]=a[i+j];zCounter++;}}
调用方法将数据写入,方法的形式参数分别是测站编号,x轴数据,y轴数据,z轴数据
createHtmlContext(site,xData,yData,zData);}}}else{
如果文件没有找到就等待两秒
System.out.println(“[Err]Cannot found file “+rawHandleController+”.raw!”);
Thread.sleep(2000);}
文件处理计数器自增,准备处理下一个文件
rawHandleController++;
处理完文件后,就删除它防止混淆。
if(file.exists()) {file.delete();}
当文件积累到10000个时,就重新从0开始计
if(rawHandleController>=99) {rawHandleController=0;}}}
文本处理函数,因为文件都是单行结构,所以只读一行即可。
public static int[] getLineFromTxt(File file, String split) throws Exception{
BufferedReader br = new BufferedReader(new FileReader(file));
String firstLine = br.readLine(); String[] arrs = firstLine.split(” “);int[] arr = new int[arrs.length];
for(int i = 0; i< arr.length; i++){arr[i] = Integer.parseInt(arrs[i]);}if(br!= null){br.close();br = null;}return arr;}
这个方法生成html,实际上是生成js脚本,生成的脚本和现有网页相互连接,完成了我们在流览器中的显示。
public static void createHtmlContext(int a,int xData[],int yData[],int zData[]) throws Exception{
这里原本有错误写入机制,后来因为速度原因被删除。这里一组数据用于接收单个测站以前的数据,加上新的数据后重新写入文件
String xDataFromHtml = “”;String yDataFromHtml = “”;String zDataFromHtml = “”;
创建一个文件对象,准备写入数据,它实际上是一个脚本供前端调用
File f = new File(“handled”+File.separator+a+”.js”);
如果单个测站数据文件不存在,我们需要新建一个js文件
if(!f.exists()) {
创建一个新的文件
f.createNewFile();
创建输出流
BufferedWriter out = new BufferedWriter(new FileWriter(f));
逐步拼接出符合要求的js文件,将数据添加到其中
这里是新文件的制作过程,它是一个网页数组的格式
out.write(“var arr1 = [“);for(int i=0;i<xData.length;i++) {out.write(xData[i]+”,”);}
out.write(“]; var arr2 = [“);for(int i=0;i<yData.length;i++) {out.write(yData[i]+”,”);}
out.write(“]; var arr3 = [“);for(int i=0;i<zData.length;i++) {out.write(zData[i]+”,”);}
out.write(“];”);out.flush();out.close();}else {
如果文件不存在,创建输出流。
BufferedReader br = new BufferedReader(new FileReader(f));
读取原来的文件,因为是单行结构,所以只读一行即可
String res = br.readLine();
创建正则运算式并匹配,意图抽取原来文件中X轴的数据
Pattern p1=Pattern.compile(“var arr1 = \\[(((\\w*|-\\w*),)*)\\]; var arr2 = \\[“);
Matcher m1=p1.matcher(res);
如果有匹配到if(m1.find()){
将匹配到的值也就是原来文件X轴的数值赋值给xDataFromHtml
xDataFromHtml= m1.group(1);
如果xDataFromHtml的长度大于1000,即有10秒以上的数据资讯,则清空
if(xDataFromHtml.length()>100*10) {xDataFromHtml=””;}
将我们新的数据拼接在原来数据的后面
for(int i=0;i<xData.length;i++) {xDataFromHtml+=xData[i]+”,”;}}
下面两组代码是匹配Y轴的数据,和X轴是类似的,但是注意,他们的正则运算式是不同的
Pattern p2=Pattern.compile(“\\]; var arr2 = \\[(((\\w*|-\\w*),)*)\\]; var arr3 = \\[“);
Matcher m2=p2.matcher(res);
if(m2.find()){yDataFromHtml= m2.group(1);
if(yDataFromHtml.length()>100*10) {yDataFromHtml=””;}
for(int i=0;i<yData.length;i++) {yDataFromHtml+=yData[i]+”,”;}}
下面两组代码是匹配Z轴的数据,和X轴是类似的,但是注意,他们的正则运算式是不同的
Pattern p3=Pattern.compile(“\\]; var arr3 = \\[(((\\w*|-\\w*),)*)\\];”);
Matcher m3=p3.matcher(res);if(m3.find()){
zDataFromHtml= m3.group(1);
if(zDataFromHtml.length()>100*10) {zDataFromHtml=””;}
for(int i=0;i<zData.length;i++) {zDataFromHtml+=zData[i]+”,”;} }
BufferedWriter out = new BufferedWriter(new FileWriter(f));
将最后的保存资讯写入硬碟
out.write(“var arr1 = [“);
out.write(xDataFromHtml);
out.write(“]; var arr2 = [“);out.write(yDataFromHtml);out.write(“]; var arr3 = [“);out.write(zDataFromHtml);out.write(“];”);out.flush();out.close();} }
我们再稍微提一下我们再软体内部文件处理时候,所运用的方法。
String xDataBuffer=””;String yDataBuffer=””;String zDataBuffer=””;Date d=new Date();String filepathPrefix=”handled”+File.separator+a+File.separator+(d.getYear()+1900)+File.separator+
d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator+d.getMinutes()+File.separator;for(int i=0;i<xData.length;i++) {xDataBuffer=xData[i]+”,”;}for(int i=0;i<yData.length;i++) {yDataBuffer=yData[i]+”,”;}for(int i=0;i<zData.length;i++) {zDataBuffer=zData[i]+”,”;}txtTools.appTxt(xDataBuffer,filepathPrefix+”x.txt”);txtTools.appTxt(yDataBuffer, filepathPrefix+”y.txt”);txtTools.appTxt(zDataBuffer, filepathPrefix+”z.txt”);
可以发现,原理是类似的,只是转成了对于txt的操作。
4.3错误处理记录器(ErrHandle.jar)(已分拆)
会实时监控文件的生成情况,系统的占用情况。
儅缓存积压达到域值暂停制作器或儅文件异常暂停处理器,致命性错误重启系统并记录。同时记录对测站的访问和操作情况。由于此模块耗费大量的系统资源,并不适用于这个实时性要求比较高的程式,故取消了这个模块,同时将这个模块的重要功能分拆在其他模块中。
4.4单测站数据文件(xxxx.js)
处理器最终生成文件是一个javascript脚本,保存在handled文件夹下,封装了最后的结果(实时更新),前端用户在递交请求时,同时会请求这个js文件,将内容一并发送给客户端(浏览器)。这里我们再改版中将他移动到了用户UI中。
4.5前端用户交互文件组(index.html,xxxx.html等多项文件)
最顶级的交互页面由index.html支撑,用户选择测站后会带领进入相应的测站html。
4.6用户动作捕捉
原则上来说,我们应该制作大量的按钮,但是由于原始按钮都不太美观,而每个按钮添加图片和定位又显得耗时耗力,于是,我们使用相关滑鼠位置捕捉。
首先我们对于每个父容器的点击行为进行定位
contentPane.addMouseListener(new MouseAdapter() {@Override
public void mouseClicked(MouseEvent e) {checkPoint(e.getXOnScreen(),e.getYOnScreen());}});
请注意,我们定义了一个checkPoint方法,接下来我们来讲解它。
可以看出,我们是将按钮看作一个矩形,对其范围进行检测,当用户有点击事件时检测是否在这个区域。
private void checkPoint(int x,int y) {if(ptc(x,y,1498,190,1699,256)) {//do something}}
private boolean ptc(int x,int y,int a,int b,int c,int d) {if(x>=a&&x<=c&&y>=b&&y<=d) {return true;}else{return false;}}
4.7用户主介面
实际上介面设计的代码很多,我们将其全部忽略,只讲述我们认为重要的核心代码
获取一个时间的实例化类。
Date d=new Date();
我们可以看到,这里主要是配合制作器去找寻文件。它会去寻找一个当前时间的文件,它是制作器保存的,然后我们直接拿来用,将它显示在我们的面板中。
String filepathPrefix=”handled”+File.separator+nr.getText()+File.separator+(d.getYear()+1900)+File.separator+d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator;
然而,如何定义当前时间呢,我们有定义,当用户查询时间不到当前分钟的30秒,我们会去获取上一分钟的数据,如果当前分钟已经过了30秒,我们获取当前分钟的数据。
if(d.getSeconds()>30){filepathPrefix+=d.getMinutes()+File.separator;}else{filepathPrefix+=(d.getMinutes()-1)+File.separator;}String filepath=””;
用户查询XYZ轴中的哪一个就去找那个文件
switch(axid) {case 0:filepath=filepathPrefix+”x.txt”;break;case 1:filepath=filepathPrefix+”y.txt”;break;case 2:filepath=filepathPrefix+”z.txt”;break;}
try {File f=new File(filepath);String data=””;
如果文件存在我们就读取它
if(f.exists()) {data=txtTools.readTxt(filepath);
但是我们的系统尚未正式部署,所以时常遇到没有找到文件的情况,此时用乱数代替
}else{for(int i=0;i<100;i++) {data+=(((int)(Math.random()*6))-3)+”,”;}}
4.8数据点抽象技术
我们的数据量很大,如果全部显示,显然是不现实的,但有时候,由于特殊情况我们的数据量有比较小,所以,我们无法给出一个固定值。我们需要对全部的点进行统计,给出一个适当的值,使得最终数据点不超过100个。
String outData=””;if(data.length()>100) {String temp[]=data.split(“,”);
int m=(int)(data.length()/100)-1;if(m==0) {m=1;}
for(int i=0;i<((int)(temp.length/m))-1;i++) {outData+=temp[i*m]+”,”;}
}else {outData=data;}
String title=nr.getText()+”测站在”+(d.getYear()+1900)+”年”+d.getMonth()+”月”+d.getDate()+”日”+d.getHours()+”时”+d.getMinutes()+”分的地震监测数据”;
showChat(title,outData);
这里我们用到了图表绘制,我们将在下一个小结进行讨论。
4.9图表绘制技术
对于这个软体,我们使用jfreechart来完成我们的图表绘制,它必须要提供一个数据集,然后对表格进行定义,但是到目前位置,我尚未找到合适的融合方法。同样的,我们省略大量的代码,只留下核心的。
定义表格显示方法public static void showChat(String title,String hourDataChain) {
创建一个标准表格StandardChartTheme mChartTheme = new StandardChartTheme(“”);
定义主题ChartFactory.setChartTheme(mChartTheme);
定义数据集CategoryDataset mDataset = GetDataset(dataChain);
创建JFreeChart mChart = ChartFactory.createLineChart();
定义数据集public static CategoryDataset GetDataset(String dataChain)
分隔原数据oneData=hourDataChain.split(“,”);
添加到数据集mDataset.addValue(Integer.parseInt(onerData[i]), “震幅”, “”+i);}
4.10设置修改与提交
我们在软体中会有大量的数据提交,但是我们不会在显示类中直接处理用户参数的变更,而是将它拷贝为两份,其中一份直接保存在内存,另一份传入硬碟,以确保用户在掉电后仍然可以在下次启动时获得他需要的设置,我们有多个设置文件,它们在使用时会拼接成一个完整的指令串。
首先我们创建一个文本文件
String sa=txtTools.readTxt(“data/settingA.txt”);
然后我们需要获取用户的所有填入参数并和原本的参数进行逐个比较,如果有不一致的再进行更改。String[] sp=sa.split(“,”);
String[] np=new String[] {t1.getText(),t2.getText(),t3.getText(),t4.getText(),t5.getText()”};
for(int i=0;i<18;i++) {if((!””.equals(np[i]))&&!sp[i].equals(np[i])) {sp[i]=np[i];}}String as=””;
for(int i=0;i<18;i++) {as+=sp[i]+”,”;}para.execOnce=0;para.userSetting=as+para.userSetting;
txtTools.writeTxt(as, “data/settingA.txt”);note(“更改提交”,”已提交您的更改!”);
4.11垃圾回收
我们在上一个步骤设定了参数,那么如何将他们应用在我们的垃圾回收中,其实原理比较简单。
首先我们获取整体运行开关,它是整个的开关
if(para.isreleaseCanWork==1) {
获取日期参数
Date d=new Date();
如果这几个设置参数不是-1的话,因为我们设置-1就是让这个选项失效 if(Integer.parseInt(ua[6])!=-1&&Integer.parseInt(ua[7])!=-1&&Integer.parseInt(ua[8])!=-1) {
首先是单次时间验证,就是检测用户设置的时间是否等于现在的时间,如果等于,就删掉指定测站的内容。 if(d.getHours()==Integer.parseInt(ua[6])&&d.getMinutes()==Integer.parseInt(ua[7])) {del(ua[3]);}}
下面几句是回圈执行语句,因为我们的release本身就是回圈执行的,所以我们不用加另外的回圈。我们将之前执行的时间和现在的时间进行比较,如果发现差距比用户设定的时间小,我们就执行删除指令,同时更新上次执行时间。 if(Integer.parseInt(ua[9])!=-1&&Integer.parseInt(ua[10])!=-1&&Integer.parseInt(ua[11])!=-1) {
int timec=Integer.parseInt(ua[9])*3600+Integer.parseInt(ua[10])*60+Integer.parseInt(ua[11]);
intnowtime=d.getHours()*3600+d.getMinutes()*60+d.getSeconds();if(nowtime-para.lasttime>timec) {del(ua[3]);}}
单次执行和上面的做法相似,就不再赘述。 if(Integer.parseInt(ua[12])!=-1&&Integer.parseInt(ua[13])!=-1&&Integer.parseInt(ua[14])!=-1&&Integer.parseInt(ua[15])!=-1) {if(d.getYear()+1900==Integer.parseInt(ua[12])&&d.getMonth()==Integer.parseInt(ua[13])&&d.getDate()==Integer.parseInt(ua[14])&&d.getHours()==Integer.parseInt(ua[15])) {para.execOnce=1;
del(ua[3]);}}
4.12测站资料搜寻
所有测站的资料被事先保存在一个siteNames文件中,它使用全局参数,同样,他的每个参数都用@分隔,这样在之后的处理中,我们就获得了一个新的数组,在数组之间搜寻可以比较快的找到资料,比如我们需要测站的消息,那么它一定的4的倍数,同样区域就是4的倍数加一。例如在主介面有这样的定义:
我们获取所有测站的全部资料
String ast[]=siteNames.allSiteList.split(“@”);for(int i=0;i<ast.length;i++) {和我们的选择进行对比,可以知道我们选的是区域,然后前进2位就是编号,后退两位就是纬度。
if(ast[i].equals(ne.getSelectedItem())) {nr.setText(ast[i-2]);gx.setText(ast[i+1]);gy.setText(ast[i+2]);}
4.13资料库技术
资料库本该使用一个类进行复用处理,但我们使用每个定制化的查询节省时间,首先我们需要获得一个连接实例。我们直接使用连接桥进行连接。
Class.forName(“com.mysql.cj.jdbc.Driver”);Connectionconn= DriverManager.getConnection(“jdbc:mysql://”+para.ip+”:”+para.port+para.remotePath, ” “, ” ” );
然后我们需要定制几个查询与更新方法。
比如我们支持透过姓名和手机号找人,这里我们写出通过姓名找人的方法。
public static String searchByName(String username) throws Exception {
Connection conn=init();String result = “”;PreparedStatement cmd=conn.prepareStatement(“select * from eqr where name='”+username+”‘;”);ResultSet set=cmd.executeQuery();while (set.next()) {result+= set.getInt(“id”)+”,”; result+= set.getString(“name”)+”,”;result+= set.getString(“card”)+”,”;result+= set.getString(“phone”)+”,”;}
set.close();conn.close();return result;}
再比如我们的修改密码的方法:
public static boolean update(String username,String password) throws Exception {
首先检测想要修改的用户是否存在
String tempQueryResult=query(username);if(tempQueryResult!=null) {
获得连接和执行语句。
Connection conn=init();PreparedStatement psql;
进行sql执行
psql = conn.prepareStatement(“update eqr set password = ‘”+password+”‘ where name='”+username+”‘;”);psql.executeUpdate();return true;}else {return false; }}
4.14设置解析与模型实践
我们通过时间来分隔我们需要保存的文件,这一点在之前已经讲过Date d=new Date();
我们取出记忆体中用户所有的设置,并设置文件案名String ua[]=para.userSetting.split(“,”);String filepathPrefix=”handled”+File.separator+a+File.separator+(d.getYear()+1900)+File.separator+d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator+d.getMinutes()+File.separator;for(int i=0;i<xData.length;i++) {
首先实现我们的单点测量,取出各种参数和流过的每个数据进行比较和测算
if(ua[18].length()==4) {if(a==Integer.parseInt(ua[18])) {if(xData[i]>=Integer.parseInt(ua[20])) {
if(para.reqCount<Integer.parseInt(ua[19])) {para.reqCount++;}else {new sendAlert().sendBySite((a+””));para.reqCount=0;}} }}
多点测量和但点类似,但是由于我们是多个测站,所以需要再加一个回圈,比较所有测站的运行情况。我们定义测站的参数应该大于等于4,因为就算一个测站也应该有4个单位长度if(ua[21].length()>=4) {String[] sitesub=ua[21].split(“,”);for(int j=0;j<sitesub.length;j++) {if(a==Integer.parseInt(sitesub[j])) {if(xData[i]>=Integer.parseInt(ua[23])) {if(para.reqCount<Integer.parseInt(ua[22])) {para.reqCount++;}else {new sendAlert().sendBySite(a+””);para.reqCount=0;}}} } }
我们的设置中运行用户执行一些动作,那么这些动作我们会直接调用系统指令。 if(“1”.equals(ua[24])) {exec(“shutdown -s -t 30”);}else if(“2”.equals(ua[24])) {exec(“”);}
4.15灾害特色短信
我们运行用户自定义灾难指令字串,同样,这是保存在数组中的,它的形式是这样的public static String areaRep=”RB-100,RB-100MSG,RB-101,RB-101MSG”前者保存室内区域,后者保存区域内发生地震的短信提醒,然后,当出发地震时,我们去资料库检索所有该区域用户的手机号码,直接发送短信。我们有查询手机号码的定义:
首先获取连接Connection conn=init();String result = “”;
写入查询语句String sql=”select * from eqr where area='”+area+”‘;”;
执行查询语句PreparedStatement cmd=conn.prepareStatement(sql);
获得结果ResultSet set=cmd.executeQuery();while (set.next()) {result+= set.getString(“phone”)+”,”;}
关闭连接set.close(); conn.close();return result;
1.任务本身具有很高的即时性,同时大量数据的保存和分析也对程式本身的效率提出了严格的要求。300+的测站每秒钟600short的数据,并且24小时没有停歇,我们的处理速度甚至更不上数据传来的速度,虽然之后我们将接收和处理的工作分开,然而随着时间的累积,他们之间的差值仍然是我们不容忽视的问题。
2.本人对网页的部分不是很熟悉,再js的操作,以及不刷新更新数据的方面花了很多时间实作。我们最后采用js进行连接的工作,但是这样同样会比较耗费资源。同时我们在动态解析js上也遇到了一些问题,导致本来应该实现一个的范本必须要覆蓋所有的测站,这样冗余的设计同样也是不科学的,但是介于我们每次调试都会出现不显示的问题,直到现在我们仍然还是使用单个测站一个文件的方式,希望之后得到改进。
3传递的数据不是都为1200的单位,有时候会出现200的报警资讯还有一些杂讯,那么这对处理也提出了要求。同时我们的数据流并没有明显的界限,在所有混杂数据中找到我们需要的数据也是一个比较大的挑战。
4.测站数据js动态加载问题。
这个模块本应该根据表单或参数传递动态加载js地址的,但是由于dom在加载完毕流已经关闭,所以无法使用字元拼接或document.write()或getParamter()得到传递参数,所以目前程式使用的是最原始的多html显示方法,希望这个问题得到解决。
我使用以下代码获取url参数
希望获得<script type=”text/javascript” src=$.getUrlParam(‘siteNumber’)+”.js”></script>的效果,至少获得
<script type=”text/javascript” src=siteNumber+”.js”></script>的效果,然而事实证明这都是不正确的。我直接用java批量生成html的方法。
5遍历文件数组越界问题
我们在遍历文件时,使用以下语句 for(int i = 0; i< a.length; i++),但是儅检测到1200数据资讯时,我们需要向后看3个数据以验证1200是否是包裹长度讯息,然而,如果1200出现在文件的最后末尾3个数据位置时,a[i+3]就会导致数组越界,经过实际测试,错误率为1.14%,此问题已初步解决。异步处理原因在7中讨论。 6测站资讯显示问题 项目要求实时将测站数据显示给用户,但这是比较困难的,主要有两个方面的问题: 数据量太大,单个测站1秒单轴将产生100个数据,则每点从容器右移到左仅可用时百分之一秒,这无论是人眼还是浏览器本身都是很难接受的。即使我们做固态显示,同样是数据量的问题,也会使得图片难以看清。(10秒单站单轴资讯,见下图)
如果我们做数据抽样显示,就会大量损失数据,也与我们预期目标不符。已有初步解决方案。
7异步解析问题
解析器与制作器会有一定的时间差距,儅文件数量少时影响有限,但儅时间长,文件数量多时,差距明显,会使显示数据严重滞后(初版中(含错误处理器),处理器速度只有制作器的10%,速度相差率为百分之九十),已有初步解决方案。[更新:经过代码优化,制作器速度和处理器速度相差率已降至千分之四]为什么不采用实时处理?我认为严格意义上的实时处理是不存在,因为即使实时处理socket的数据,但是从计算到存盘再到一些必要的判断,是必然需要一定时间的,哪怕是微秒级差距,也会在长期运行中逐步放大。同时,本项目产生的文件数量巨大,不适宜写入记忆体,硬碟的存储过程也不太可能让本项目实时的过程。即使用tcp协议,也会使得远程资料传递滞后。项目中要用到回溯功能,也就是一些操作会在读取后要求查看这个数据的前一个,然而如果实时处理,前一个资料早已丢弃,唯一解决的办法还是要一个空间,可哪个是我们需要前一个的数据的本身呢,我们需要不断的保存路过的数据,这样会严重拖慢系统的速度。实时处理必须要将制造器和处理器写在一起提高了耦合性降低了内聚性。分开写也符合常用的思维流程。
六.未来展望与改进空间
首先由于时间仓促,有些地方并不是很完善,导致有些功能没有很好的实现。比如我们虽然保存了用户css的文件,但我们并没有再网页中实际连接它。再者,我们有高级编程模式的想法,但由于时间所限,即使我们留下了相关的位置,功能上还是有很多欠缺。程式有很多禁不起推敲的地方,比如升级参数在记忆体中还有设置保存两份,却没有在开始连接硬碟。同时由于数据量太大,虽然设想都是正确的,然而实际运行中,尤其是多点测量却极慢的拖住了程式的速度,如果是有限的资料倒不会产生太大的问题,但遗憾的是,由于数据是源源不断传来的,每秒钟的误差逐渐累积,最后会形成一个较大的误差值,这既是我们遇到的挑战,也是我们未来改进的空间。还有我们在实作过程中,会发现部分测站没有数据,而且我们的程式资源消耗比较大,有时写入会发生错误,当我们的查询器没有返回资料时,为了不发生空指针错误并为了程式的美观,我们会用乱数来填充制作,然而,这在一个成熟的系统中是不会出现的,所以我希望在程式的各方面问题得到改进后,能够在稳定性和即时性上取得突破。
本程式的顺利完成首先要感谢我们的指导教授<动漫技术宅隐私保护>老师,他给予我们很多建设性的想法,使得专案充满了创意;同时,他也擅长解决我们遇到的困难,很多疑难的问题,我们百思不得其解,但在询问老师后都得到了很好的解决。他也积极鼓励我们和学长相互交流,取得了在专案之外的知识。另外,在整个专案的过程中,老师让我们可以合理的分配时间,使我们既完成了专题又没有影响其他科目的学习。老师以其富有想像力的设计,严谨的态度,专业的知识让我们敬佩。可以说,没有老师的辛勤指导,就没有今天我们能够呈现的程式。
其次,我们还要感谢学长的帮助和指导。由于伺服器在学校内,很多次由于断电等原因暂停使用。但无论何时,只要我们有需要,学长都会赶到实验室帮我们开启机器。有些作业系统的配置问题,也请教过学长,得到了很好的解答。
在程式编写的过程中,我们还查阅了一些网路上的资料,帮助我们解决了很多困难,在此我对这些无私帮助他人的程序员表示由衷的感谢。
最后,我还要感谢学校给我们这次实作的机会,台科的理论课都很优秀和实用,但是我们也需要一定的实作来充实我们的经验。而这次实作,虽然经历很多挫折,却是我们前进的源泉和动力。
九.总结与心得
本次程式主要由我负责,可以说一开始我们并没有很好的思路,因为即使是传来的数据格式了解都不是非常深刻,再加上之前没有写过类似的scoket长连接程式,所以感觉挑战还是很大的。尤其到最后,发现数据量实在太大,即使将程式优化到极限,仍然跟不上我们的速度,所以我索性不再即时处理数据,而是将数据先保存下来,再慢慢处理,所以就有了原始文件制作器和之后的分析处理过程平行分开的形式。
但是这时候,我发现网页的连接又是一个困难,页面内容是固定的,如何在每次刷新获得不同的数据。在静态网页技术上,这几乎是不可能的任务,于是我想到了,先把网页的主体做好,把数据以js的形式连接到外部,然后由我们的主程式创建和修改我们的外部js文件,并且在网页中添加了刷新语句,让我们能够即时获得最新的数据报告。但是这样的展示设计并不能实现我们之前所想像的功能,首先要通知客户,就要有地震的模型以及他们的预测,同时帐户系统,短信的发送都是必不可少的,他们都有着各自的困难。
首先我们想出的几种模型,但是他们显然不是非常的实用,在和教授的交流过程中我们得知真正的地震预警会有严格的公式和周期定义,我们这样以单点预测,虽然可用,但会存在误差,而且一旦地震,对其深度和一些详细参数也不太了解。另外,我们虽然定义了多个站点,但是等于把预警的任务推给了用户,用户如何知道哪些站点可以组成阵列,只能依靠直觉,并没有一个系统有效的方法。但是我们的系统可以作为一个基础,它也并非没有实用价值。
我们的帐户系统秉持我一贯做软体的经验,除了代码有些冗余,但效果确实有效和完整的。同时,经过测试,确实将我们定义的区域短信全部发送到了我们资料库的用户手机中。整个过程没有发现明显差错。
同时,在介面的显示上,我一改以前传统按钮的复杂布局,直接使用检测座标的方式来触发程式功能,节约了不少时间,但这也有一些问题,我们的按键没有效果,比较死板,于是我使用弹窗的形式来中和这样的负面效果,使得按键得到了合理的反馈。
我花费了很多时间在完成页面的数据连续显示上,直到最后,我们都没有获得一个很好的方案,其中的最大原因,是我对网页的设计不太熟悉,不能很好的运用ajax和note.js,这方面的知识虽然我有意去学习,然而由于学业紧张,并没有取得很好的效果,所以最后专题快要结案时,我改变程式设计方向,从B/S架构转为C/S+B/S架构,完成了很多数据级的任务处理,使得我们的实作内容有实际的运作意义。
我想,对于我来说,最大的问题可能是时间上的,毕竟我们的设想复杂,而又有很多其它学业,没有给我们反复研究的时间和机会。另外,是心理上的,原地打转的挫折感会让我们困惑。但这正是我们要学习的地方,所谓在失败中进步,在挫折中成长,相信经过这次实作,我们会以更专业的知识,更积极的态度投身到之后的学习中。
<动漫技术宅隐私保护>
2018年12月31日
[报告结束,谢谢。]