


圖1:识别物体步驟

圖2:物體識別的廣泛應用
对于传统的神经网路分割方法,有着参数过于庞大,极大的减慢了处理的速度;除此之外,当卷积步长大于一的时候,会降低图像的分辨率,从而损失很多重要的信息,剩余的信息又会经过池化层,加剧了对于信息的丢失,这对于我们的分割任务都是非常不利的。而早期的deeplab算法,由于没有解码(decoder)模块,由于存在一些特征扩展,会使得在encoder的时候变慢;同样因为没有解码器,无法和原始的图像信息进行连接,会造成一些细节难以恢复。为了解决这些问题,在deeplabv3中添加了一个简单而有效的解码器,形成了编码-解码的结构。它有如下好处:1.首先保证了图像分辨率不会因为池化而造成损失。2.加入ASPP大大降低了参数并增加了感受野。不再满足于原有encoder出来的结果,而是通过加入解码器对原来的结果进行优化。总结来说就是克服了传统标准卷积的缺点,对物体的边界进行更快更有效的恢复。
我们需要使用空洞卷积和编解码技术更快更准确的完成语言分割任务,需要介绍deeplabv3+技术,下面介绍它的framework。首先我们需要输入一张图片,它的分辨率是512*512的,拥有RBG三个通道,也就是说是一张彩色图像,然后我们模型的训练和优化,第一步是将其输入到Resnet中,关于Resnet的部分我们接下来会专门提到,我们把Resnet的结果进行ASPP处理。在ASPP中,我们选用不同的Rate进行Convlution,它们分别是1*1和3*3的conv,其中3*3又分为6,12,18三种不同rate,在分别计算出结果后,我们可以获得5个32*32*256的结果,我们把它们进行concatenate,随后我们将结果再经历一个1*1的Filer,目的是为了降低参数,由此我们通过整个encoder获得了一个32*32*256的局部特征。总结起来就是说Encoder就是原来的DeepLabv3,注意点有2点:输入尺寸与输出尺寸比(output stride = 16),最后一个stage的膨胀率rate为2。Atrous Spatial Pyramid Pooling module(ASPP)有四个不同的rate,额外一个全局平均池化。这里我们需要额外介绍depthwise convolution(P5右上)是在每个通道上独自的进行空间卷积,pointwise convolution是利用1×1卷积核组合前面depthwise convolution得到的特征。为什么说要用它呢?因为它能够保持性能的同时大大减少计算量,假若输入2通道的特征,输出3通道特征,卷积核大小为3×3正常的卷积参数量为2x(3×3)x3=54,而深度可分离卷积参数量为2x3x3 + 2x1x1x3 =24其中第一部分为depthwise convolution(2x3x3),第二部分为pointwise convolution(2x1x1x3)。我们再来关注decoder的情况,先把encoder的结果上采样4倍,然后与resnet中下采样前的Conv2特征concat一起,注意融合低层次信息前,先进行1×1的卷积,目的是降通道(例如有512个通道,而encoder结果只有256个通道)。再进行3×3的卷积,最后上采样4倍得到最终结果。这样我们在encoder阶段获得了局部特征,在decoder阶段融合了全局特征,可以获得比较好的结果。
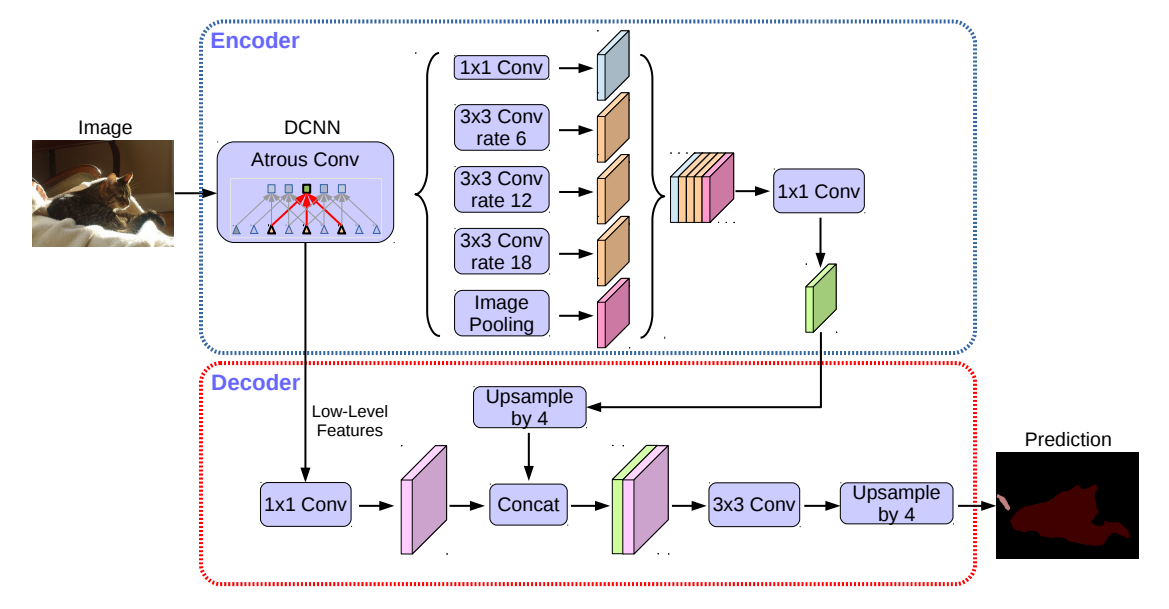
圖3:deeplabv3+的架構
我们在获取不同尺寸的资讯时,通常会有几种不同的方法,1)首先是图像金字塔,小的卷积去捕捉远程上下文,而大的卷积用来保留详细的信息,我们通过多个不同尺度的卷积获得不同层次的信息,再将它们融合,但这样做会耗费大量的gpu资源,基本在理论上的有效而实际上是不存在的2)第二个是编码器-解码器结构:此模型由两部分组成:(a)编码器,其中特征图的空间尺寸逐渐减小,因此在较深的编码器输出中更容易捕获更长的范围信息;以及(b)解码器,其中物体的细节和空间尺寸逐渐得到恢复。3)更深层次的空洞卷积:此模型包含各种不同卷积的分层模块,以对远程上下文进行编码。4)空间金字塔池:该模型采用空间金字塔池捕获多个范围的上下文。从DeepLabv2开始提出了空间金字塔池化(ASPP),其中具有不同rate的并行卷积层捕获多尺度信息。
deeplabv3+实现了deeplabv3的基本内容,包括编码-解码结构中的编码器,除此之外,使用了编码器来包含丰富的语义讯息,同时一个简单而有效的解码器来恢复物体边界的资讯,编码层允许我们借助ASPP萃取不同尺寸的信息。其中我们介绍的深度可分离卷积是一种有效的操作,用来减少计算成本和参数量,并保持良好的性能。
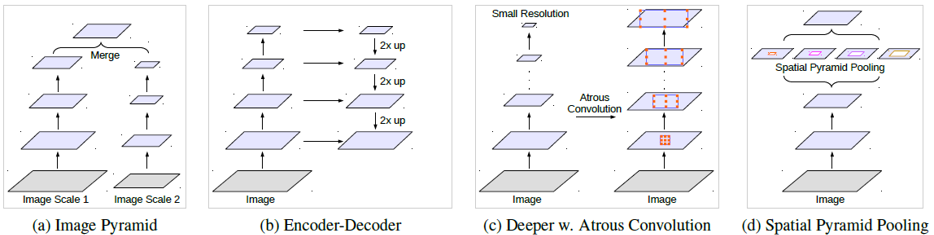
圖4:對於捕捉不同尺度的上下文,我們可以使用不同的架構。
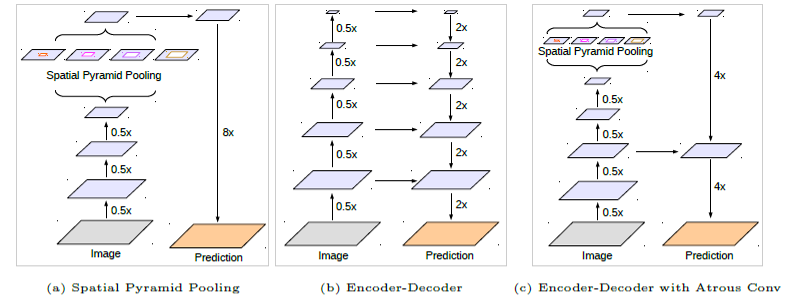
圖5:多種不同的手段幫助我們提升deeplabV3的結果
我们对几个具体的问题进行讨论,首先是DACNN,它的定义是基于ResNet的DeepLabv3,它在第1,2,3的block中的下采样使用卷积步长为2的3*3的max pooling实现的,block4是对5,6,7的复制,而ASPP则应用在第4,5,6层。包括不同类的输出分割图,请参阅:用于语义分割的学习反卷积网络。在训练的过程中,我们的batch size可以是4,8,12,16的任何值,我们的初始learning rate为0.007,而每运行三万次进行一次learning rate的更新,在另外一组试验中,我们将初始的learning rate调节到0.001,同样也是三万次进行一次更新。
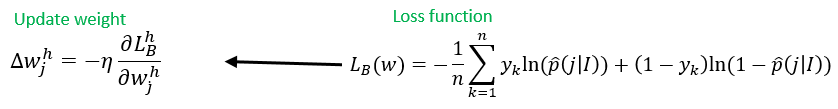
圖5:Learning rate

圖6:Learning rate的更新
接下来介绍的是空洞可分离卷积,它分为两个部分,空洞深度卷积,类似从空间上去解决问题,另外是从点的角度去考虑问题,我们需要把一个9*9*3的下采样成1*1*1的卷积,我们先使用一个3*3*1的过滤器进行下采样,得到1*1*3的卷积,随后再次使用1*1*3的卷积得到一个1*1*1的下采样结果,在整个下采样的过程中,我们结合了空洞卷积的技术,代替我们原有的第一步,也就是Depthwise Conv。在我们的实作中也将深度可分离卷积分为深度卷积和点卷积,深度卷积可以对每个层都起到作用,点卷积是将不同层的内容综合起来。我们使用卷积步长为2的卷积去代替第一步的深度卷积,希望扩大感受野。
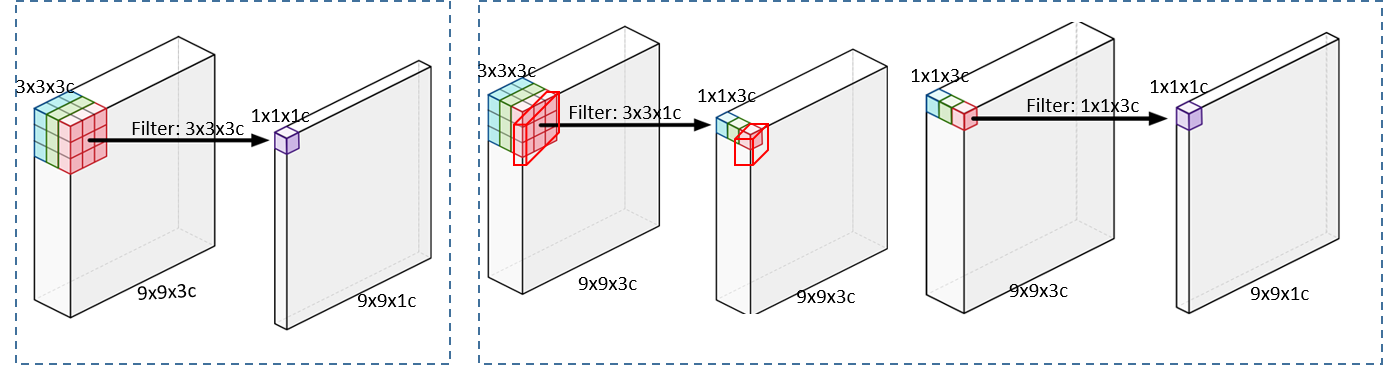
圖7:空洞可分离卷积
由于我们一开始使用了ResNet,在这里我们对它做一下简要介绍,一般来说,随着神经网路层数的增加,结果会有一定的提升,然而过多的层也会造成梯度下降,一些局部细节被丢失,为了合理解决这个问题,resnet提出跨过一些层,而将原始信息和结果进行运算合并,这种思想在现在很多主流的神经网络架构上都有应用,Resnet就是使用这种方法且经过了101层的conv,它每一个节点的输入和输出都是相同,即28*28*256。当这个尺寸的输入进来时,我们使用64个filter对它进行投影,得到的结果再经过3*3*64.最后得出结果。
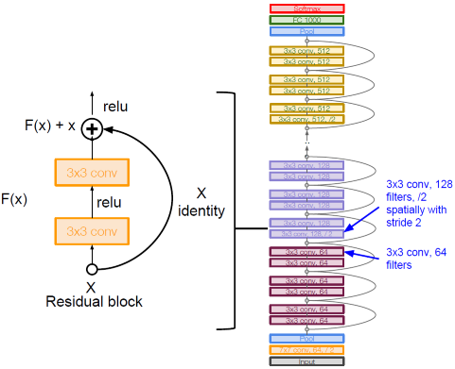
圖8:Resnet架構