

目錄 一.研究動機...........................................................2 二.數據源介紹.......................................................3 三.系統介面和基本功能...............................................4 3.1主介面.......................................................4 3.2歷史資料查詢.................................................5 3.3預警與動作...................................................6 3.4資訊與救援...................................................7 3.5賬號與數據...................................................8 3.6網頁發佈.....................................................9 3.7即時網頁顯示................................................10 四.技術細節........................................................11 4.1原始文件製作器..............................................11 4.2處理器......................................................12 4.3錯誤處理記錄器..............................................15 4.4單測站數據文件..............................................15 4.5前端用戶文件交互組..........................................15 4.6用戶動作捕捉................................................15 4.7用戶主介面..................................................16 4.8數據點抽象技術..............................................16 4.9圖表繪製技術................................................16 4.10設置修改與提交.............................................17 4.11垃圾回收...................................................17 4.12測站資料搜尋...............................................17 4.13資料庫技術.................................................18 4.14模型實踐...................................................18 4.15災害特色短信...............................................19 五.遇到的困難......................................................20 六.未來展望和改進空間..............................................22 八.致謝............................................................23 九.總結與心得......................................................24
通常認爲,地震可以製造廣泛的傷害,而由於人類還沒有完全瞭解地殼內部的活動和構造,所以地震的預測是非常困難的,即使以目前的科學水準,仍然難以對其發生原因,機制和預測方法進行系統的認知和總結。但是在地震發生之後,我們可以對其進行預警,利用地震波到達地面的時間差來指導地面上的人進行避難工作。現有系統已經比較完善,我們可以收到手機短信或者推送,但是由於是針對一個區域的群發機制,很多人在地震發生時不知所措,不知道在哪里避難,食物和水源在哪里,這造成了潛在的危險。另外,在地震發生後,我們往往被動尋找傷者,而沒有對區域人員的一個全局把握,到底有多少人,有沒有聯繫電話等等。同時對於研究人員,也缺乏一個可以即時觀察地震數據,或者回溯之前的地震情況的方法。我們需要一個系統,來幫助我們解決上述我們提到的問題。
我們的數據源來自中央研究院分佈在全臺灣的三百餘個測站,其主要使用三聯科技股份有限公司的Palert地震 P 波警報儀。每個測站每秒至少會產生1200個原始數據,通過socket通訊即時傳輸到臺灣科大伺服器。我們的軟體即時讀取這些資訊來進行分析和預警工作。由於每秒傳遞的數據量大,對軟體的即時性和可靠性提出了非常大的考驗。
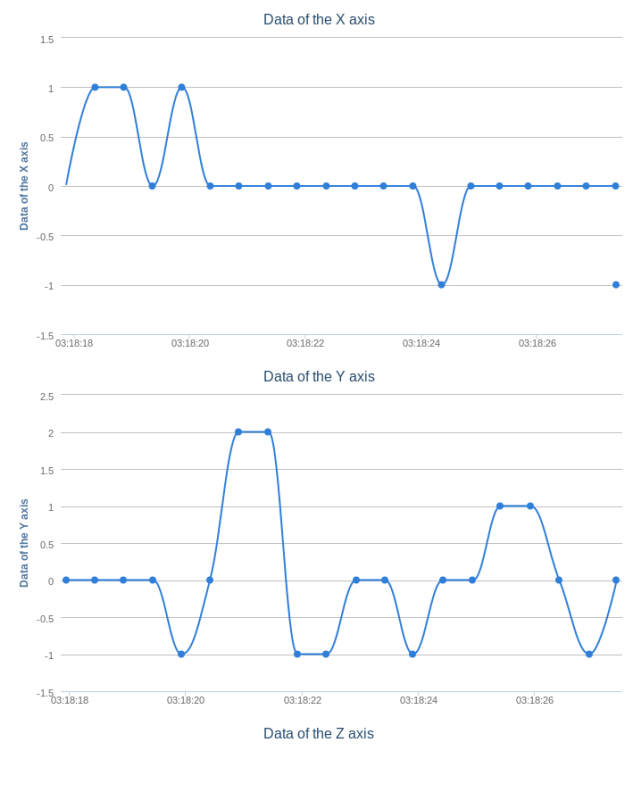
我們已經提到,測站每秒鐘會傳遞1200個原始資料,但是我們主要用到的是其中的一部分,它包含了此測站在一秒鐘在空間XYZ中的移動情況。下表提供了一些資料每個short的定義。但值得注意的,這已經是處理完成的樣式了,實際的接收數據,我們需要用兩個byte來拼合成一個short,這一點在此不多做贅述。
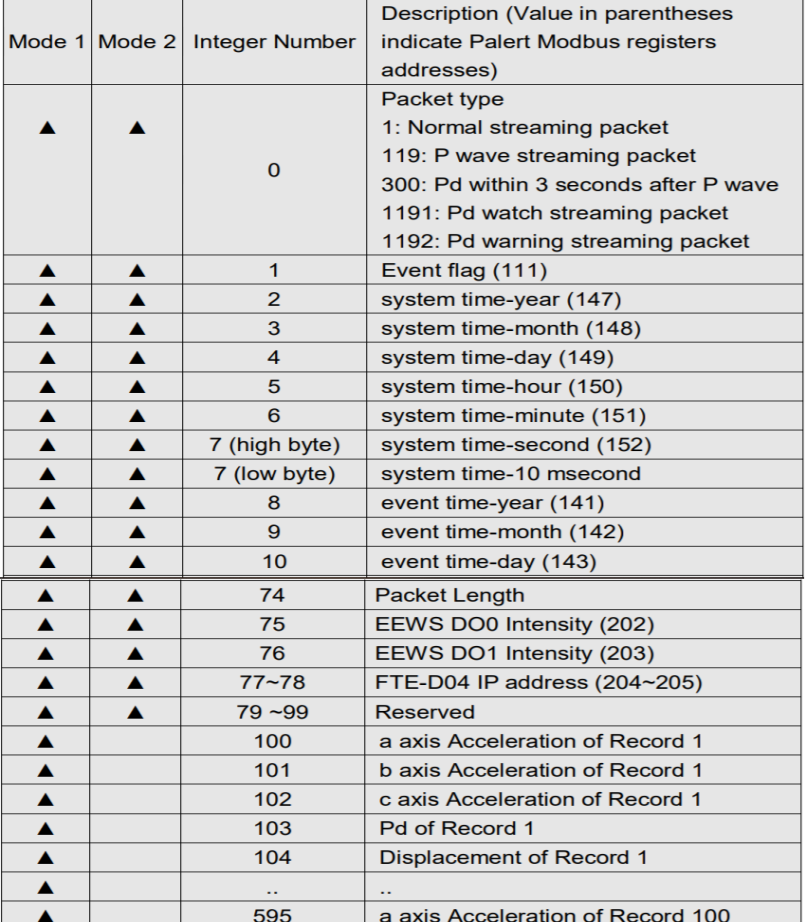
3.1主介面
這是我們的主介面,也是我們最開始看到的操作面板。
首先我們需要選擇一個區域,點擊右側的“獲取”按鈕,可以獲得該區域的所有測站。我們可以對這些測站進行分別查看,點擊“送出查詢”,可以看到在下方顯示測站的編號,位置和備註,此時,右側並沒有地震圖表的顯示,因為我們還需要指定我們所查看的坐標軸。如果把探測器看作一個放在空間中心的物體,則它會有三種運動方向,平面上的前後和高度的上下,這樣構成了一個三維坐標系,我們可以對每個維度的震動進行分別查看。這樣的圖形幾乎是實時的,理論誤差在30秒以內,而由我們系統生成的網頁版本,其誤差可以在10秒以下。雖然我們的系統在設計之初有著較高的時間敏感性,但直到實作結束,時間誤差依然有10秒左右,其中原因會在之後討論。
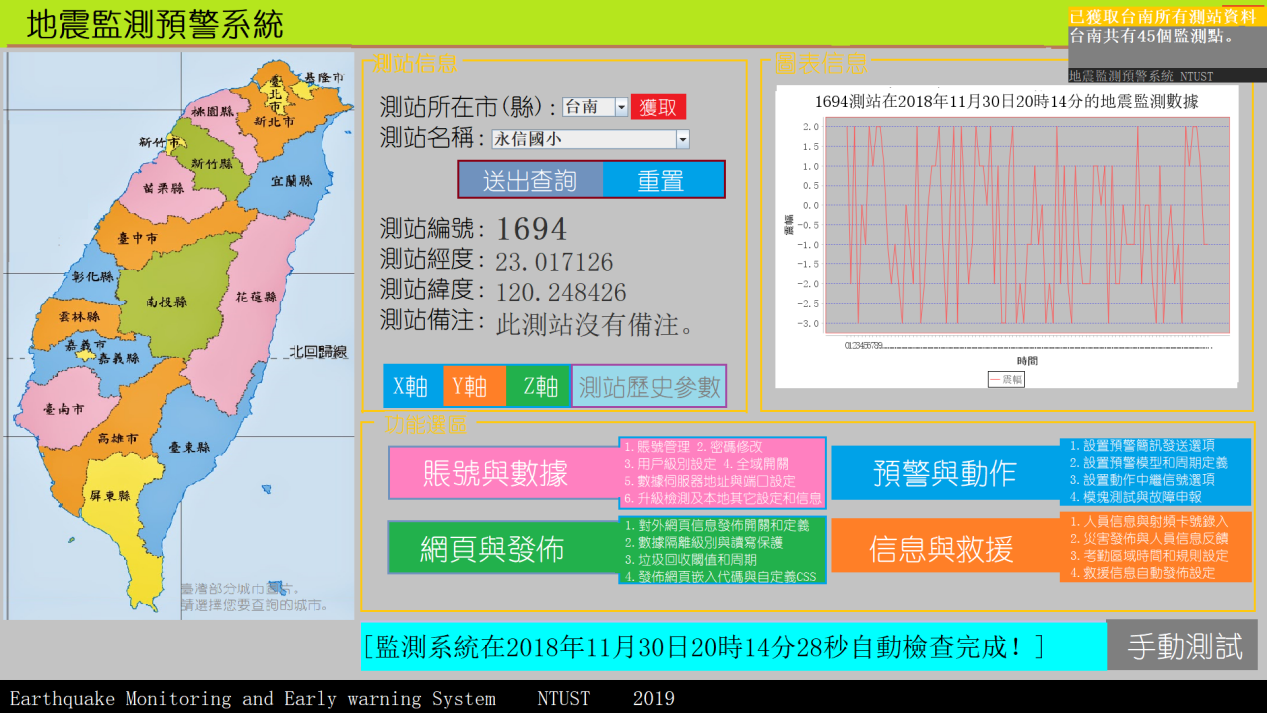
3.2歷史資料查詢
當然我們還可以獲得任意時間和任意測站的參數情況。我們可以使用系統提供的歷史功能,幫我們查看已經發生的地震行為,但是由於我們的數據量非常大,對此我們引入了垃圾回收概念。有可能我們查詢的測站在沒有保護的情況下資料已經被刪除,所以我們要保障數據的存在性。
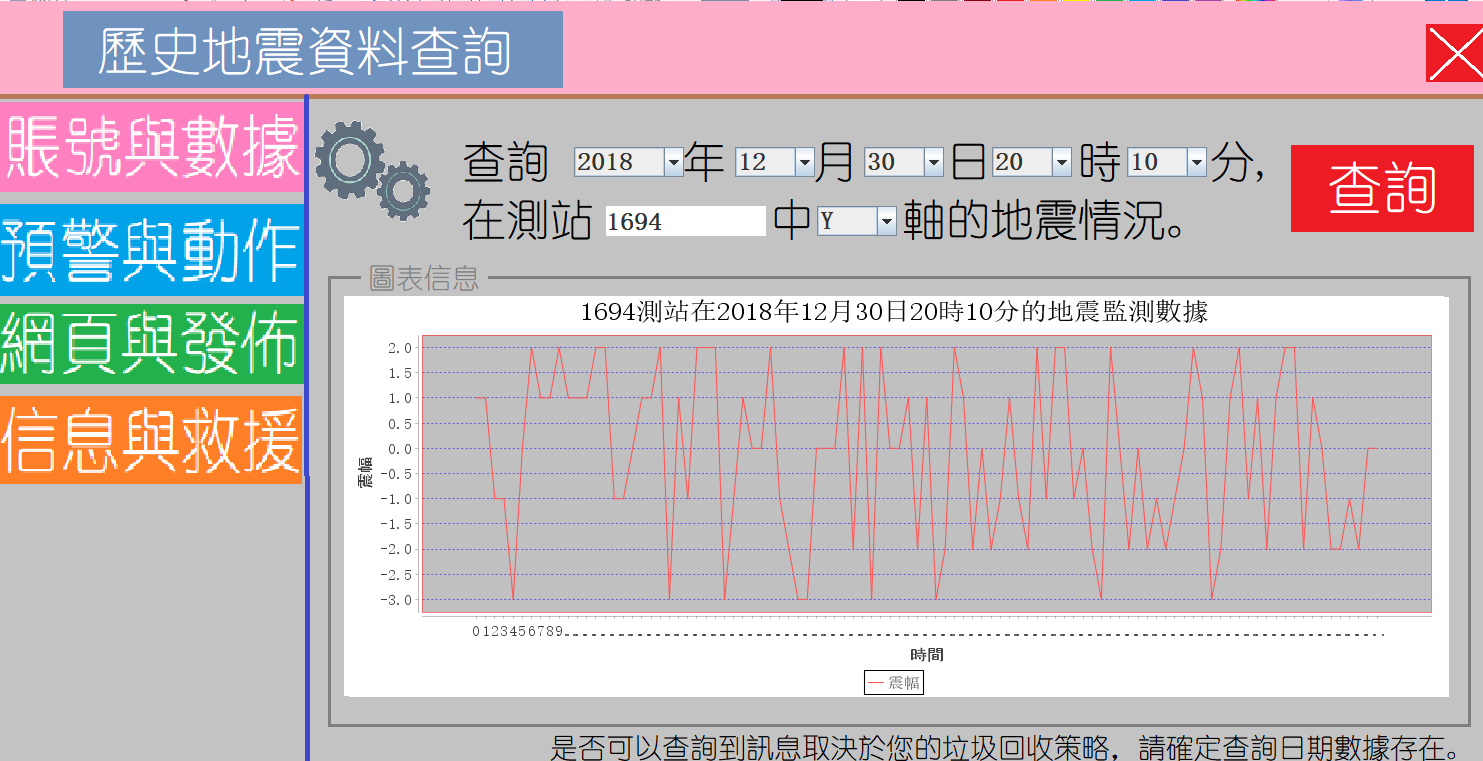
3.3預警與動作
我們允許用戶自行定義模型,即定義什麼情況是發生了地震,以及地震發生後的動作。
首先是單點模式,它只能專注一個測站,去看它是否產生了地震信號,但也正是於此,它的效率非常高,幾乎不會對處理數據造成影響。
其次是多點複雜模式,我們允許用戶對多個測站進行監控,他們用逗號分隔,和單一測站檢測的機制相同,所有測站一旦發生用戶定義的情況,就會出發地震報警。所謂報警,我們主要通過短信通知所有在此區域的用戶,這個在之後會詳細討論。
我們還設想了高級的複雜模型,主要對所有數據執行區域聚合和長短週期定義,使得他們具備時間上的關聯性。但是由於實際測試中,這樣會嚴重影響我們數據的處理速度,所以在最終版本的軟體中,我們暫時去掉了這個功能。
接下來是動作中繼,也就是我們檢測到發生了地震,也給用戶發送了短信,可是然後呢,於是我們支持一些基本的功能,比如可以關機保護系統,也可以通過發送數據包或寫入為文件的方式,給其他系統通報地震信號。我們還允許用戶自定義任意的執行語句。這些語句只要是符合命令提示字元,都可以被準確的執行。最後,我們提供了短信的開關,可以自由的打開短信發送的管道。
但是,我們如何通知用戶來告知地震呢,首先需要介紹我們的帳號功能。
3.4資訊與救援
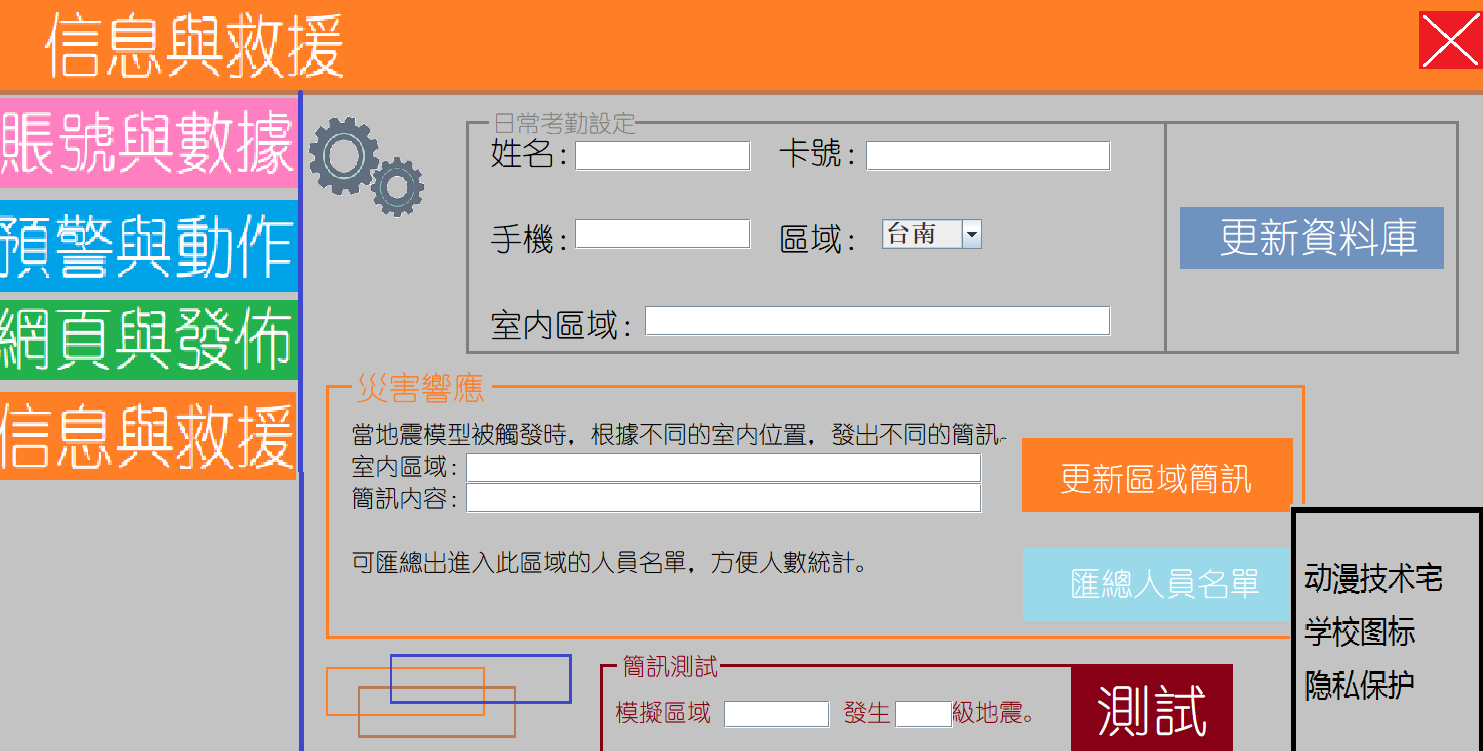
我們允許一個新的用戶註冊,用戶需要提供他的姓名手機和所在區域,同樣也要提供室內區域,我們的室內區域將會在接下來進行定義,所謂室內區域我們會單獨定義他的報警資訊,比如用戶在一樓,我們會指導他找到出口,當用戶在高樓層時,我們會告訴他如何避難以及找到食物和水。同時,我們也可以匯總出每個室內區域的全部人員名單和他們的聯繫方式,對接下來的救援工作有著比較大的協助。最後我們可以讓用戶進行測試來嘗試對區域內的用戶發送提示短信。
3.5帳號與數據
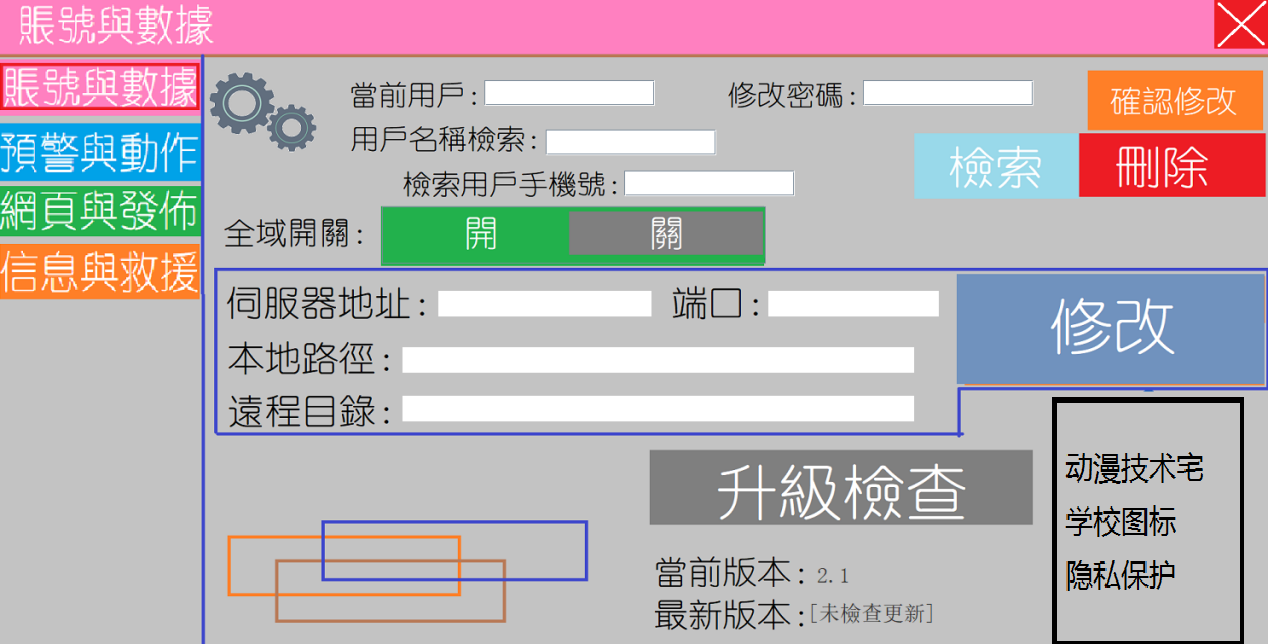
對於4中定義的用戶,我們可以對其進行修改密碼,同時通過姓名和手機號碼,我們也可以對用戶的訊息進行查找,同樣的對於接收伺服器和端口以及本地路徑,也可以由用戶自定義,方便有遷移需求的用戶。
3.6網頁與發佈
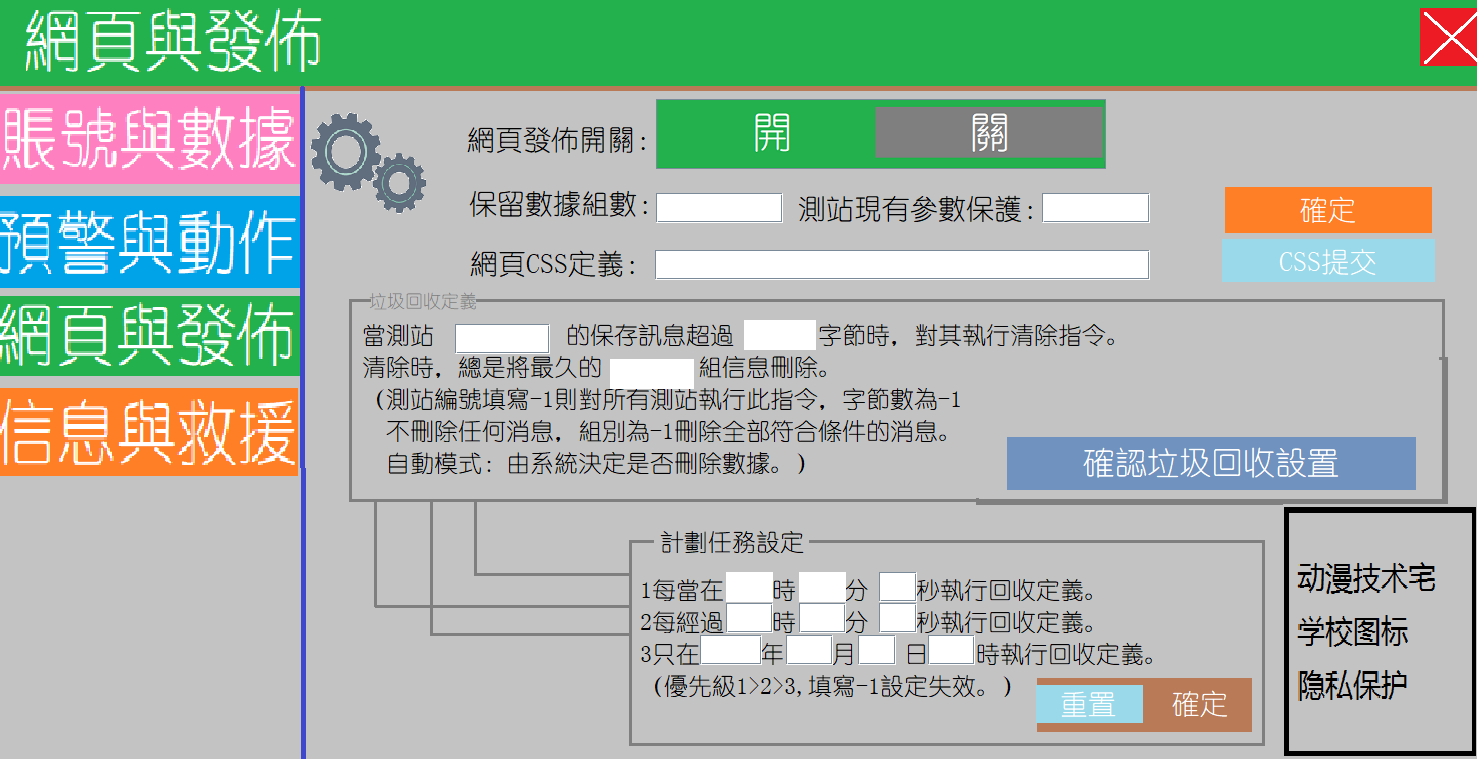
我們可以在帳號與發表中定義網頁的開關,即是否允許用戶查看即時的地震情況,我們也對一些CSS定義進行擴展,方便前端網頁的人員進行引用。我們定義了三種垃圾回收的方式1.第一種時定時回收,設定一個時間,然後在這個時間回收它。2.其次是每隔多久進行一次回收的定義。最後是只進行一次的回收方式。用戶可以根據自己的情況對應回收模式,但是由於我們會產生大量數據,用戶需要保證磁片空間的剩餘量。
3.7即時網頁顯示
首先我們對本軟體中所有遇到的技術進行逐個解析:
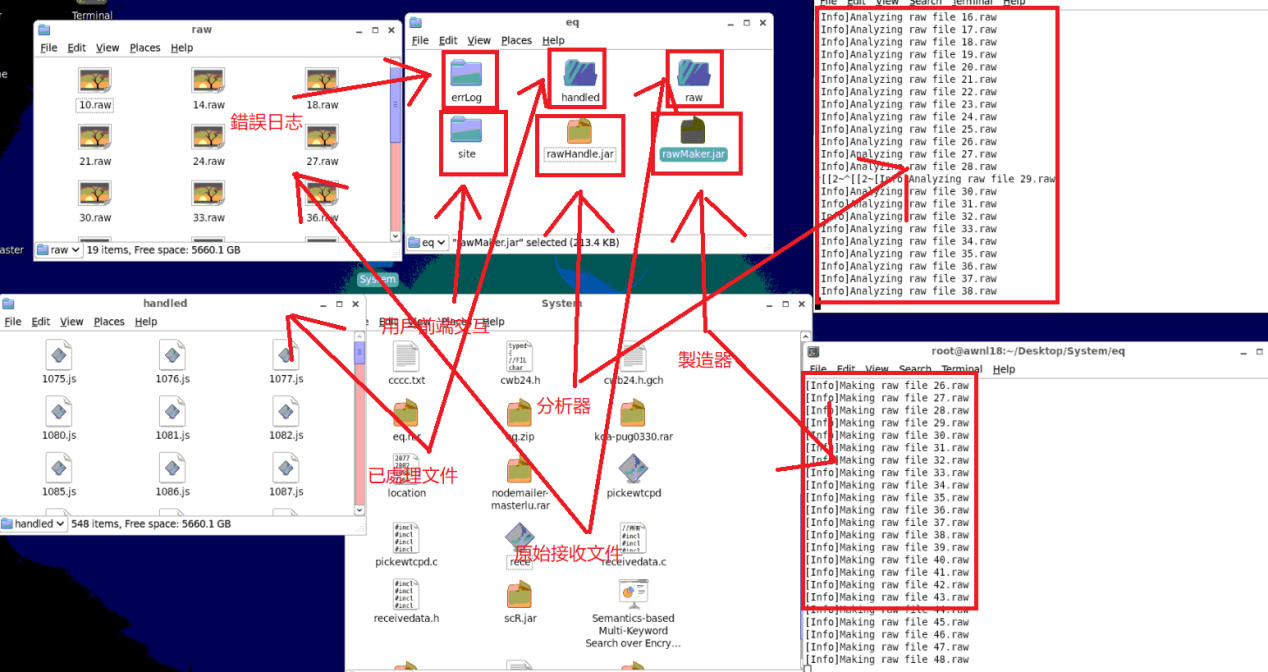
我們先定義幾個基本模組
4.1原始文件製作器(RawMaker.jar)
主要用來接收來自socket中的訊息,並將它解碼,分割寫入磁碟中,它是始終的無條件的運行的,不受程式其他模塊的干擾,也不要求有對齊或其他解析功能。它生成後綴名為raw的文件並保存在raw文件夾下。
我們先定義一個位元組轉換方法,用於將兩個byte 拼接成一個short
public static short byteTransform(byte a,byte b) {
return (short) ((a << 8)| (0x00FF & b));}
另外,容器也是必不可少的,用來作為buffer保存我們的數據
public static byte[] itb(InputStream in) throws IOException{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] data = new byte[1204];
int count = -1;
int MaxWaitTimes=0;
while(((count = in.read(data,0,1204)) != -1)&&MaxWaitTimes<1) {
outStream.write(data, 0, count);
MaxWaitTimes++;}
data = null;
return outStream.toByteArray();
}
}
記錄單個文件中的short數據數目,把它的初始值設為350*1202,是希望它第一次就能進入初始化文件的操作流程,它會在初始化後重新變為0
int rawRecCounter=350*1202;
全局計數器,記錄當前的檔案名稱,有控制文件迴圈記錄的功能
int rawRecGlobalCounter=-1;
BufferedWriter out = null;
開啟Socket管道
Socket s = new Socket(“140.110.141.23”,23000);
InputStream is = s.getInputStream();
我們的接收工作原則上不會停止,所以是while讓它永遠執行
while(true){
檢測是否要建立一個新的文件,如果計數器表明已經產生了所有測站1秒的數據則新建立一個文件。
if(rawRecCounter>=350*1202) {
一個新的文件建立了,我們把計數器清零。
rawRecCounter=0;
如果全局計數器大於等於100,則讓它為0,覆蓋100秒前的數據文件。
if(rawRecGlobalCounter>=99+1) {rawRecGlobalCounter=0;}else{System.out.println(“[Info]Making raw file “+(rawRecGlobalCounter+1)+”.raw”);
新建或覆蓋全局計數器指定的文件
rawRecGlobalCounter++;}
新建文件對象,它等於全局計數器的名稱
File writename = new File(“raw”+File.separator+rawRecGlobalCounter+”.raw”);
新建文件
writename.createNewFile();
獲取輸出緩存
out = new BufferedWriter(new FileWriter(writename));}
將is流中的數據一行一行傳入byte數組,方便之後的分析。
byte[] bytes = itb(is);
我們現在對單行byte數據進行處理
for(int i=0;i<bytes.length;i=i+2) {
把後面的byte和前面的byte粘貼,組成一個short
out.write(byteTransform(bytes[i+1],bytes[i])+” “);
當前文件記錄的short數自增
rawRecCounter++;}
刷新緩存
out.flush();}}
至此,我們完成對於原始scoket數據包到原始文件的轉換過程。
4.2處理器(Handle.jar)
主要用來解析製作器生成的文件,將混雜著預警資訊的所有測站(單秒)原始文件,解析分割到各自測站的文件資訊中,它可以創建並修改文件,並有一定的客觀糾錯功能(覆蓋寫入)。同時它也控制著單個測站保存數據的最大值,避免磁盤空間溢出。
處理器承載這用戶網頁的顯示和我們軟體內部的顯示,由於提供給用戶的數據沒有經過過濾和處理,所以速度會比較快。在這裏,我們會忽略軟體內部的文件處理方法,只講述給用戶流覽器的呈現方法,因為方法是及其類似,而網頁處理的過程相對簡單。
首先我們需要一個文件處理計數器,用於標識我們處理到第幾個文件,和製作器配合,初始數值範圍是0到9999,當達到9999時,自動變為0,防止文件過多積壓磁片和int形變量溢出。
int rawHandleController=0;
我們需要不停的處理製作器的資訊,所以是無限迴圈
while(true) {
System.out.println(“[Info]Analyzing raw file “+rawHandleController+”.raw”);
生成一個文件對象,它將在之後讀取製作器的預處理文件,使用separator方法是為了相容系統路徑在Linux的使用。
File file = new File(“raw”+File.separator+rawHandleController+”.raw”);
檢查文件存在性,通過與else配合,如果文件不存在,我們會讓系統等待兩秒之後再做檢查,通常文件不存在是由於處理器先於製作器啟動,或製作器在寫入數據時發生延緩,這類情況通常較少出現
if(file.exists()) {
承載容器,接納製作器生成的全部文本內容,供之後分析。
int[] a = getLineFromTxt(file,” “);
預先聲明3個int形數組,他們將在之後承載單個文件
單個測站的xyz軸訊息。每個軸有100個資料。
int xData[] =new int[100];int yData[] =new int[100];int zData[] =new int[100];
這裏記錄的時測站編號,因為我們是通過之後的長度和時間來定位數據的,這時候測站編號已經被解析,我們需要一個變數來保存測站的編號,給以後使用。
int site=0;
遍曆文件容器中的每一個數據,1200為安全邊界,防止在解析到測站編號和時間後測站資訊不完整。
for(int i = 0; i< a.length-1200; i++){
如果我們解析到一個1200的數據且它的後面跟了一個正確的年份,我們則認為它是一個測站資訊的開始。我們可以再細化時間檢查來提高它的準確度,但根據實際檢測情況,這樣的檢查已經夠用了,目前沒有差錯報告。
if(a[i]==1200&&a[i+3]==2018&&i<a.length-1200) {
回溯一個數據,將其記錄在變數site中。
site=a[i-1];
這一組數據記錄和控制寫入在單個測站單軸的數組位置。
int xCounter=0;int yCounter=0;int zCounter=0;
根據具體要求,我們解析全文數據的102位(正文數據的100位),到數據包結束
for(int j=102;j<=601;j++) {
其中,每組數據(5個)有兩個是我們不需要的,我們把它捨棄,只留下需要的部分
if(j%5==2) {xData[xCounter]=a[i+j];xCounter++;}if(j%5==3) {yData[yCounter]=a[i+j];yCounter++;}
if(j%5==4) {zData[zCounter]=a[i+j];zCounter++;}}
調用方法將數據寫入,方法的形式參數分別是測站編號,x軸數據,y軸數據,z軸數據
createHtmlContext(site,xData,yData,zData);}}}else{
如果文件沒有找到就等待兩秒
System.out.println(“[Err]Cannot found file “+rawHandleController+”.raw!”);
Thread.sleep(2000);}
文件處理計數器自增,準備處理下一個文件
rawHandleController++;
處理完文件後,就刪除它防止混淆。
if(file.exists()) {file.delete();}
當文件積累到10000個時,就重新從0開始計
if(rawHandleController>=99) {rawHandleController=0;}}}
文本處理函數,因為文件都是單行結構,所以只讀一行即可。
public static int[] getLineFromTxt(File file, String split) throws Exception{
BufferedReader br = new BufferedReader(new FileReader(file));
String firstLine = br.readLine(); String[] arrs = firstLine.split(” “);int[] arr = new int[arrs.length];
for(int i = 0; i< arr.length; i++){arr[i] = Integer.parseInt(arrs[i]);}if(br!= null){br.close();br = null;}return arr;}
這個方法生成html,實際上是生成js腳本,生成的腳本和現有網頁相互連接,完成了我們在流覽器中的顯示。
public static void createHtmlContext(int a,int xData[],int yData[],int zData[]) throws Exception{
這裏原本有錯誤寫入機制,後來因為速度原因被刪除。這裏一組數據用於接收單個測站以前的數據,加上新的數據後重新寫入文件
String xDataFromHtml = “”;String yDataFromHtml = “”;String zDataFromHtml = “”;
創建一個文件對象,準備寫入數據,它實際上是一個腳本供前端調用
File f = new File(“handled”+File.separator+a+”.js”);
如果單個測站數據文件不存在,我們需要新建一個js文件
if(!f.exists()) {
創建一個新的文件
f.createNewFile();
創建輸出流
BufferedWriter out = new BufferedWriter(new FileWriter(f));
逐步拼接出符合要求的js文件,將數據添加到其中
這裏是新文件的製作過程,它是一個網頁數組的格式
out.write(“var arr1 = [“);for(int i=0;i<xData.length;i++) {out.write(xData[i]+”,”);}
out.write(“]; var arr2 = [“);for(int i=0;i<yData.length;i++) {out.write(yData[i]+”,”);}
out.write(“]; var arr3 = [“);for(int i=0;i<zData.length;i++) {out.write(zData[i]+”,”);}
out.write(“];”);out.flush();out.close();}else {
如果文件不存在,創建輸出流。
BufferedReader br = new BufferedReader(new FileReader(f));
讀取原來的文件,因為是單行結構,所以只讀一行即可
String res = br.readLine();
創建正則運算式並匹配,意圖抽取原來文件中X軸的數據
Pattern p1=Pattern.compile(“var arr1 = \\[(((\\w*|-\\w*),)*)\\]; var arr2 = \\[“);
Matcher m1=p1.matcher(res);
如果有匹配到if(m1.find()){
將匹配到的值也就是原來文件X軸的數值賦值給xDataFromHtml
xDataFromHtml= m1.group(1);
如果xDataFromHtml的長度大於1000,即有10秒以上的數據資訊,則清空
if(xDataFromHtml.length()>100*10) {xDataFromHtml=””;}
將我們新的數據拼接在原來數據的後面
for(int i=0;i<xData.length;i++) {xDataFromHtml+=xData[i]+”,”;}}
下麵兩組代碼是匹配Y軸的數據,和X軸是類似的,但是注意,他們的正則運算式是不同的
Pattern p2=Pattern.compile(“\\]; var arr2 = \\[(((\\w*|-\\w*),)*)\\]; var arr3 = \\[“);
Matcher m2=p2.matcher(res);
if(m2.find()){yDataFromHtml= m2.group(1);
if(yDataFromHtml.length()>100*10) {yDataFromHtml=””;}
for(int i=0;i<yData.length;i++) {yDataFromHtml+=yData[i]+”,”;}}
下麵兩組代碼是匹配Z軸的數據,和X軸是類似的,但是注意,他們的正則運算式是不同的
Pattern p3=Pattern.compile(“\\]; var arr3 = \\[(((\\w*|-\\w*),)*)\\];”);
Matcher m3=p3.matcher(res);if(m3.find()){
zDataFromHtml= m3.group(1);
if(zDataFromHtml.length()>100*10) {zDataFromHtml=””;}
for(int i=0;i<zData.length;i++) {zDataFromHtml+=zData[i]+”,”;} }
BufferedWriter out = new BufferedWriter(new FileWriter(f));
將最後的保存資訊寫入硬碟
out.write(“var arr1 = [“);
out.write(xDataFromHtml);
out.write(“]; var arr2 = [“);out.write(yDataFromHtml);out.write(“]; var arr3 = [“);out.write(zDataFromHtml);out.write(“];”);out.flush();out.close();} }
我們再稍微提一下我們再軟體內部文件處理時候,所運用的方法。
String xDataBuffer=””;String yDataBuffer=””;String zDataBuffer=””;Date d=new Date();String filepathPrefix=”handled”+File.separator+a+File.separator+(d.getYear()+1900)+File.separator+
d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator+d.getMinutes()+File.separator;for(int i=0;i<xData.length;i++) {xDataBuffer=xData[i]+”,”;}for(int i=0;i<yData.length;i++) {yDataBuffer=yData[i]+”,”;}for(int i=0;i<zData.length;i++) {zDataBuffer=zData[i]+”,”;}txtTools.appTxt(xDataBuffer,filepathPrefix+”x.txt”);txtTools.appTxt(yDataBuffer, filepathPrefix+”y.txt”);txtTools.appTxt(zDataBuffer, filepathPrefix+”z.txt”);
可以發現,原理是類似的,只是轉成了對於txt的操作。
4.3錯誤處理記錄器(ErrHandle.jar)(已分拆)
會實時監控文件的生成情況,系統的佔用情況。
儅緩存積壓達到域值暫停製作器或儅文件異常暫停處理器,致命性錯誤重啓系統並記錄。同時記錄對測站的訪問和操作情況。由於此模塊耗費大量的系統資源,並不適用於這個實時性要求比較高的程式,故取消了這個模塊,同時將這個模塊的重要功能分拆在其他模塊中。
4.4單測站數據文件(xxxx.js)
處理器最終生成文件是一個javascript腳本,保存在handled文件夾下,封裝了最後的結果(實時更新),前端用戶在遞交請求時,同時會請求這個js文件,將內容一併發送給客戶端(瀏覽器)。這裏我們再改版中將他移動到了用戶UI中。
4.5前端用戶交互文件組(index.html,xxxx.html等多項文件)
最頂級的交互頁面由index.html支撐,用戶選擇測站後會帶領進入相應的測站html。
4.6用戶動作捕捉
原則上來說,我們應該製作大量的按鈕,但是由於原始按鈕都不太美觀,而每個按鈕添加圖片和定位又顯得耗時耗力,於是,我們使用相關滑鼠位置捕捉。
首先我們對於每個父容器的點擊行為進行定位
contentPane.addMouseListener(new MouseAdapter() {@Override
public void mouseClicked(MouseEvent e) {checkPoint(e.getXOnScreen(),e.getYOnScreen());}});
請注意,我們定義了一個checkPoint方法,接下來我們來講解它。
可以看出,我們是將按鈕看作一個矩形,對其範圍進行檢測,當用戶有點擊事件時檢測是否在這個區域。
private void checkPoint(int x,int y) {if(ptc(x,y,1498,190,1699,256)) {//do something}}
private boolean ptc(int x,int y,int a,int b,int c,int d) {if(x>=a&&x<=c&&y>=b&&y<=d) {return true;}else{return false;}}
4.7用戶主介面
實際上介面設計的代碼很多,我們將其全部忽略,只講述我們認為重要的核心代碼
獲取一個時間的實例化類。
Date d=new Date();
我們可以看到,這裏主要是配合製作器去找尋文件。它會去尋找一個當前時間的文件,它是製作器保存的,然後我們直接拿來用,將它顯示在我們的面板中。
String filepathPrefix=”handled”+File.separator+nr.getText()+File.separator+(d.getYear()+1900)+File.separator+d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator;
然而,如何定義當前時間呢,我們有定義,當用戶查詢時間不到當前分鐘的30秒,我們會去獲取上一分鐘的數據,如果當前分鐘已經過了30秒,我們獲取當前分鐘的數據。
if(d.getSeconds()>30){filepathPrefix+=d.getMinutes()+File.separator;}else{filepathPrefix+=(d.getMinutes()-1)+File.separator;}String filepath=””;
用戶查詢XYZ軸中的哪一個就去找那個文件
switch(axid) {case 0:filepath=filepathPrefix+”x.txt”;break;case 1:filepath=filepathPrefix+”y.txt”;break;case 2:filepath=filepathPrefix+”z.txt”;break;}
try {File f=new File(filepath);String data=””;
如果文件存在我們就讀取它
if(f.exists()) {data=txtTools.readTxt(filepath);
但是我們的系統尚未正式部署,所以時常遇到沒有找到文件的情況,此時用亂數代替
}else{for(int i=0;i<100;i++) {data+=(((int)(Math.random()*6))-3)+”,”;}}
4.8數據點抽象技術
我們的數據量很大,如果全部顯示,顯然是不現實的,但有時候,由於特殊情況我們的數據量有比較小,所以,我們無法給出一個固定值。我們需要對全部的點進行統計,給出一個適當的值,使得最終數據點不超過100個。
String outData=””;if(data.length()>100) {String temp[]=data.split(“,”);
int m=(int)(data.length()/100)-1;if(m==0) {m=1;}
for(int i=0;i<((int)(temp.length/m))-1;i++) {outData+=temp[i*m]+”,”;}
}else {outData=data;}
String title=nr.getText()+”測站在”+(d.getYear()+1900)+”年”+d.getMonth()+”月”+d.getDate()+”日”+d.getHours()+”時”+d.getMinutes()+”分的地震監測數據”;
showChat(title,outData);
這裏我們用到了圖表繪製,我們將在下一個小結進行討論。
4.9圖表繪製技術
對於這個軟體,我們使用jfreechart來完成我們的圖表繪製,它必須要提供一個數據集,然後對表格進行定義,但是到目前位置,我尚未找到合適的融合方法。同樣的,我們省略大量的代碼,只留下核心的。
定義表格顯示方法public static void showChat(String title,String hourDataChain) {
創建一個標準表格StandardChartTheme mChartTheme = new StandardChartTheme(“”);
定義主題ChartFactory.setChartTheme(mChartTheme);
定義數據集CategoryDataset mDataset = GetDataset(dataChain);
創建JFreeChart mChart = ChartFactory.createLineChart();
定義數據集public static CategoryDataset GetDataset(String dataChain)
分隔原數據oneData=hourDataChain.split(“,”);
添加到數據集mDataset.addValue(Integer.parseInt(onerData[i]), “震幅”, “”+i);}
4.10設置修改與提交
我們在軟體中會有大量的數據提交,但是我們不會在顯示類中直接處理用戶參數的變更,而是將它拷貝為兩份,其中一份直接保存在內存,另一份傳入硬碟,以確保用戶在掉電後仍然可以在下次啟動時獲得他需要的設置,我們有多個設置文件,它們在使用時會拼接成一個完整的指令串。
首先我們創建一個文本文件
String sa=txtTools.readTxt(“data/settingA.txt”);
然後我們需要獲取用戶的所有填入參數並和原本的參數進行逐個比較,如果有不一致的再進行更改。String[] sp=sa.split(“,”);
String[] np=new String[] {t1.getText(),t2.getText(),t3.getText(),t4.getText(),t5.getText()”};
for(int i=0;i<18;i++) {if((!””.equals(np[i]))&&!sp[i].equals(np[i])) {sp[i]=np[i];}}String as=””;
for(int i=0;i<18;i++) {as+=sp[i]+”,”;}para.execOnce=0;para.userSetting=as+para.userSetting;
txtTools.writeTxt(as, “data/settingA.txt”);note(“更改提交”,”已提交您的更改!”);
4.11垃圾回收
我們在上一個步驟設定了參數,那麼如何將他們應用在我們的垃圾回收中,其實原理比較簡單。
首先我們獲取整體運行開關,它是整個的開關
if(para.isreleaseCanWork==1) {
獲取日期參數
Date d=new Date();
如果這幾個設置參數不是-1的話,因為我們設置-1就是讓這個選項失效 if(Integer.parseInt(ua[6])!=-1&&Integer.parseInt(ua[7])!=-1&&Integer.parseInt(ua[8])!=-1) {
首先是單次時間驗證,就是檢測用戶設置的時間是否等於現在的時間,如果等於,就刪掉指定測站的內容。 if(d.getHours()==Integer.parseInt(ua[6])&&d.getMinutes()==Integer.parseInt(ua[7])) {del(ua[3]);}}
下麵幾句是迴圈執行語句,因為我們的release本身就是迴圈執行的,所以我們不用加另外的迴圈。我們將之前執行的時間和現在的時間進行比較,如果發現差距比用戶設定的時間小,我們就執行刪除指令,同時更新上次執行時間。 if(Integer.parseInt(ua[9])!=-1&&Integer.parseInt(ua[10])!=-1&&Integer.parseInt(ua[11])!=-1) {
int timec=Integer.parseInt(ua[9])*3600+Integer.parseInt(ua[10])*60+Integer.parseInt(ua[11]);
intnowtime=d.getHours()*3600+d.getMinutes()*60+d.getSeconds();if(nowtime-para.lasttime>timec) {del(ua[3]);}}
單次執行和上面的做法相似,就不再贅述。 if(Integer.parseInt(ua[12])!=-1&&Integer.parseInt(ua[13])!=-1&&Integer.parseInt(ua[14])!=-1&&Integer.parseInt(ua[15])!=-1) {if(d.getYear()+1900==Integer.parseInt(ua[12])&&d.getMonth()==Integer.parseInt(ua[13])&&d.getDate()==Integer.parseInt(ua[14])&&d.getHours()==Integer.parseInt(ua[15])) {para.execOnce=1;
del(ua[3]);}}
4.12測站資料搜尋
所有測站的資料被事先保存在一個siteNames文件中,它使用全局參數,同樣,他的每個參數都用@分隔,這樣在之後的處理中,我們就獲得了一個新的數組,在數組之間搜尋可以比較快的找到資料,比如我們需要測站的消息,那麼它一定的4的倍數,同樣區域就是4的倍數加一。例如在主介面有這樣的定義:
我們獲取所有測站的全部資料
String ast[]=siteNames.allSiteList.split(“@”);for(int i=0;i<ast.length;i++) {和我們的選擇進行對比,可以知道我們選的是區域,然後前進2位就是編號,後退兩位就是緯度。
if(ast[i].equals(ne.getSelectedItem())) {nr.setText(ast[i-2]);gx.setText(ast[i+1]);gy.setText(ast[i+2]);}
4.13資料庫技術
資料庫本該使用一個類進行複用處理,但我們使用每個定制化的查詢節省時間,首先我們需要獲得一個連接實例。我們直接使用連接橋進行連接。
Class.forName(“com.mysql.cj.jdbc.Driver”);Connectionconn= DriverManager.getConnection(“jdbc:mysql://”+para.ip+”:”+para.port+para.remotePath, ” “, ” ” );
然後我們需要定制幾個查詢與更新方法。
比如我們支持透過姓名和手機號找人,這裏我們寫出通過姓名找人的方法。
public static String searchByName(String username) throws Exception {
Connection conn=init();String result = “”;PreparedStatement cmd=conn.prepareStatement(“select * from eqr where name='”+username+”‘;”);ResultSet set=cmd.executeQuery();while (set.next()) {result+= set.getInt(“id”)+”,”; result+= set.getString(“name”)+”,”;result+= set.getString(“card”)+”,”;result+= set.getString(“phone”)+”,”;}
set.close();conn.close();return result;}
再比如我們的修改密碼的方法:
public static boolean update(String username,String password) throws Exception {
首先檢測想要修改的用戶是否存在
String tempQueryResult=query(username);if(tempQueryResult!=null) {
獲得連接和執行語句。
Connection conn=init();PreparedStatement psql;
進行sql執行
psql = conn.prepareStatement(“update eqr set password = ‘”+password+”‘ where name='”+username+”‘;”);psql.executeUpdate();return true;}else {return false; }}
4.14設置解析與模型實踐
我們通過時間來分隔我們需要保存的文件,這一點在之前已經講過Date d=new Date();
我們取出記憶體中用戶所有的設置,並設置文件案名String ua[]=para.userSetting.split(“,”);String filepathPrefix=”handled”+File.separator+a+File.separator+(d.getYear()+1900)+File.separator+d.getMonth()+File.separator+d.getDate()+File.separator+d.getHours()+File.separator+d.getMinutes()+File.separator;for(int i=0;i<xData.length;i++) {
首先實現我們的單點測量,取出各種參數和流過的每個數據進行比較和測算
if(ua[18].length()==4) {if(a==Integer.parseInt(ua[18])) {if(xData[i]>=Integer.parseInt(ua[20])) {
if(para.reqCount<Integer.parseInt(ua[19])) {para.reqCount++;}else {new sendAlert().sendBySite((a+””));para.reqCount=0;}} }}
多點測量和但點類似,但是由於我們是多個測站,所以需要再加一個迴圈,比較所有測站的運行情況。我們定義測站的參數應該大於等於4,因為就算一個測站也應該有4個單位長度if(ua[21].length()>=4) {String[] sitesub=ua[21].split(“,”);for(int j=0;j<sitesub.length;j++) {if(a==Integer.parseInt(sitesub[j])) {if(xData[i]>=Integer.parseInt(ua[23])) {if(para.reqCount<Integer.parseInt(ua[22])) {para.reqCount++;}else {new sendAlert().sendBySite(a+””);para.reqCount=0;}}} } }
我們的設置中運行用戶執行一些動作,那麼這些動作我們會直接調用系統指令。 if(“1”.equals(ua[24])) {exec(“shutdown -s -t 30”);}else if(“2”.equals(ua[24])) {exec(“”);}
4.15災害特色短信
我們運行用戶自定義災難指令字串,同樣,這是保存在數組中的,它的形式是這樣的public static String areaRep=”RB-100,RB-100MSG,RB-101,RB-101MSG”前者保存室內區域,後者保存區域內發生地震的短信提醒,然後,當出發地震時,我們去資料庫檢索所有該區域用戶的手機號碼,直接發送短信。我們有查詢手機號碼的定義:
首先獲取連接Connection conn=init();String result = “”;
寫入查詢語句String sql=”select * from eqr where area='”+area+”‘;”;
執行查詢語句PreparedStatement cmd=conn.prepareStatement(sql);
獲得結果ResultSet set=cmd.executeQuery();while (set.next()) {result+= set.getString(“phone”)+”,”;}
關閉連接set.close(); conn.close();return result;
1.任務本身具有很高的即時性,同時大量數據的保存和分析也對程式本身的效率提出了嚴格的要求。300+的測站每秒鐘600short的數據,並且24小時沒有停歇,我們的處理速度甚至更不上數據傳來的速度,雖然之後我們將接收和處理的工作分開,然而隨著時間的累積,他們之間的差值仍然是我們不容忽視的問題。
2.本人對網頁的部分不是很熟悉,再js的操作,以及不刷新更新數據的方面花了很多時間實作。我們最後採用js進行連接的工作,但是這樣同樣會比較耗費資源。同時我們在動態解析js上也遇到了一些問題,導致本來應該實現一個的範本必須要覆蓋所有的測站,這樣冗餘的設計同樣也是不科學的,但是介於我們每次調試都會出現不顯示的問題,直到現在我們仍然還是使用單個測站一個文件的方式,希望之後得到改進。
3傳遞的數據不是都為1200的單位,有時候會出現200的報警資訊還有一些雜訊,那麼這對處理也提出了要求。同時我們的數據流並沒有明顯的界限,在所有混雜數據中找到我們需要的數據也是一個比較大的挑戰。
4.測站數據js動態加載問題。
這個模塊本應該根據表單或參數傳遞動態加載js地址的,但是由於dom在加載完畢流已經關閉,所以無法使用字元拼接或document.write()或getParamter()得到傳遞參數,所以目前程式使用的是最原始的多html顯示方法,希望這個問題得到解決。
我使用以下代碼獲取url參數
希望獲得<script type=”text/javascript” src=$.getUrlParam(‘siteNumber’)+”.js”></script>的效果,至少獲得
<script type=”text/javascript” src=siteNumber+”.js”></script>的效果,然而事實證明這都是不正確的。我直接用java批量生成html的方法。
5遍歷文件數組越界問題
我們在遍歷文件時,使用以下語句 for(int i = 0; i< a.length; i++),但是儅檢測到1200數據資訊時,我們需要向後看3個數據以驗證1200是否是包裹長度訊息,然而,如果1200出現在文件的最後末尾3個數據位置時,a[i+3]就會導致數組越界,經過實際測試,錯誤率為1.14%,此問題已初步解決。異步處理原因在7中討論。 6測站資訊顯示問題 項目要求實時將測站數據顯示給用戶,但這是比較困難的,主要有兩個方面的問題: 數據量太大,單個測站1秒單軸將產生100個數據,則每點從容器右移到左僅可用時百分之一秒,這無論是人眼還是瀏覽器本身都是很難接受的。即使我們做固態顯示,同樣是數據量的問題,也會使得圖片難以看清。(10秒單站單軸資訊,見下圖)
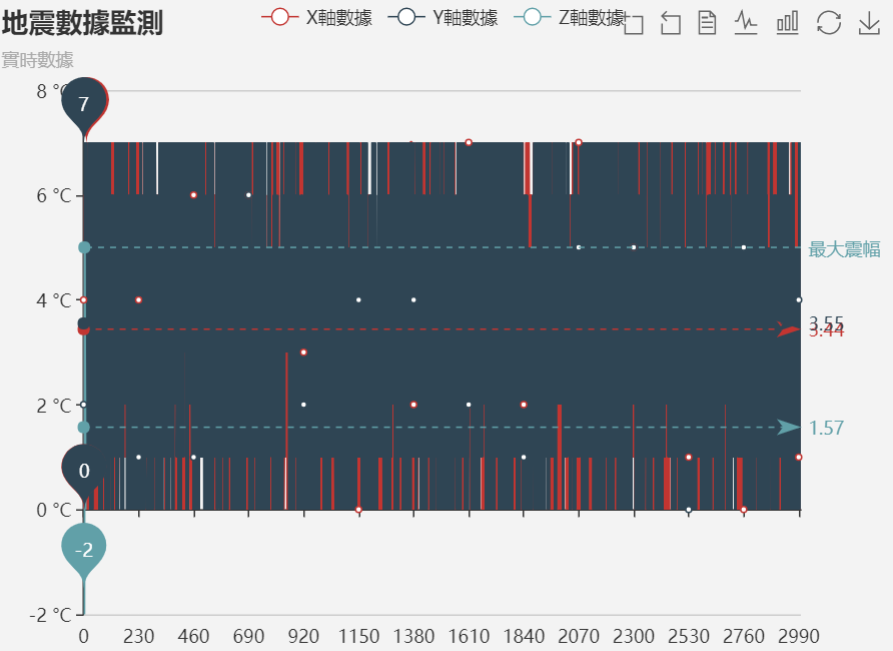
如果我們做數據抽樣顯示,就會大量損失數據,也與我們預期目標不符。已有初步解決方案。
7異步解析問題
解析器與製作器會有一定的時間差距,儅文件數量少時影響有限,但儅時間長,文件數量多時,差距明顯,會使顯示數據嚴重滯後(初版中(含錯誤處理器),處理器速度只有製作器的10%,速度相差率為百分之九十),已有初步解決方案。[更新:經過代碼優化,製作器速度和處理器速度相差率已降至千分之四]爲什麽不採用實時處理?我認爲嚴格意義上的實時處理是不存在,因爲即使實時處理socket的數據,但是從計算到存盤再到一些必要的判斷,是必然需要一定時間的,哪怕是微秒級差距,也會在長期運行中逐步放大。同時,本項目產生的文件數量巨大,不適宜寫入記憶體,硬碟的存儲過程也不太可能讓本項目實時的過程。即使用tcp協議,也會使得遠程資料傳遞滯後。項目中要用到回溯功能,也就是一些操作會在讀取後要求查看這個數據的前一個,然而如果實時處理,前一個資料早已丟棄,唯一解決的辦法還是要一個空間,可哪個是我們需要前一個的數據的本身呢,我們需要不斷的保存路過的數據,這樣會嚴重拖慢系統的速度。實時處理必須要將製造器和處理器寫在一起提高了耦合性降低了內聚性。分開寫也符合常用的思維流程。
六.未來展望與改進空間
首先由於時間倉促,有些地方並不是很完善,導致有些功能沒有很好的實現。比如我們雖然保存了用戶css的文件,但我們並沒有再網頁中實際連接它。再者,我們有高級編程模式的想法,但由於時間所限,即使我們留下了相關的位置,功能上還是有很多欠缺。程式有很多禁不起推敲的地方,比如升級參數在記憶體中還有設置保存兩份,卻沒有在開始連接硬碟。同時由於數據量太大,雖然設想都是正確的,然而實際運行中,尤其是多點測量卻極慢的拖住了程式的速度,如果是有限的資料倒不會產生太大的問題,但遺憾的是,由於數據是源源不斷傳來的,每秒鐘的誤差逐漸累積,最後會形成一個較大的誤差值,這既是我們遇到的挑戰,也是我們未來改進的空間。還有我們在實作過程中,會發現部分測站沒有數據,而且我們的程式資源消耗比較大,有時寫入會發生錯誤,當我們的查詢器沒有返回資料時,為了不發生空指針錯誤並為了程式的美觀,我們會用亂數來填充製作,然而,這在一個成熟的系統中是不會出現的,所以我希望在程式的各方面問題得到改進後,能夠在穩定性和即時性上取得突破。
本程式的順利完成首先要感謝我們的指導教授<动漫技术宅隐私保护>老師,他給予我們很多建設性的想法,使得專案充滿了創意;同時,他也擅長解決我們遇到的困難,很多疑難的問題,我們百思不得其解,但在詢問老師後都得到了很好的解決。他也積極鼓勵我們和學長相互交流,取得了在專案之外的知識。另外,在整個專案的過程中,老師讓我們可以合理的分配時間,使我們既完成了專題又沒有影響其他科目的學習。老師以其富有想像力的設計,嚴謹的態度,專業的知識讓我們敬佩。可以說,沒有老師的辛勤指導,就沒有今天我們能夠呈現的程式。
其次,我們還要感謝學長的幫助和指導。由於伺服器在學校內,很多次由於斷電等原因暫停使用。但無論何時,只要我們有需要,學長都會趕到實驗室幫我們開啟機器。有些作業系統的配置問題,也請教過學長,得到了很好的解答。
在程式編寫的過程中,我們還查閱了一些網路上的資料,幫助我們解決了很多困難,在此我對這些無私幫助他人的程序員表示由衷的感謝。
最後,我還要感謝學校給我們這次實作的機會,臺科的理論課都很優秀和實用,但是我們也需要一定的實作來充實我們的經驗。而這次實作,雖然經歷很多挫折,卻是我們前進的源泉和動力。
九.總結與心得
本次程式主要由我負責,可以說一開始我們並沒有很好的思路,因為即使是傳來的數據格式瞭解都不是非常深刻,再加上之前沒有寫過類似的scoket長連接程式,所以感覺挑戰還是很大的。尤其到最後,發現數據量實在太大,即使將程式優化到極限,仍然跟不上我們的速度,所以我索性不再即時處理數據,而是將數據先保存下來,再慢慢處理,所以就有了原始文件製作器和之後的分析處理過程平行分開的形式。
但是這時候,我發現網頁的連接又是一個困難,頁面內容是固定的,如何在每次刷新獲得不同的數據。在靜態網頁技術上,這幾乎是不可能的任務,於是我想到了,先把網頁的主體做好,把數據以js的形式連接到外部,然後由我們的主程式創建和修改我們的外部js文件,並且在網頁中添加了刷新語句,讓我們能夠即時獲得最新的數據報告。但是這樣的展示設計並不能實現我們之前所想像的功能,首先要通知客戶,就要有地震的模型以及他們的預測,同時帳戶系統,短信的發送都是必不可少的,他們都有著各自的困難。
首先我們想出的幾種模型,但是他們顯然不是非常的實用,在和教授的交流過程中我們得知真正的地震預警會有嚴格的公式和週期定義,我們這樣以單點預測,雖然可用,但會存在誤差,而且一旦地震,對其深度和一些詳細參數也不太瞭解。另外,我們雖然定義了多個站點,但是等於把預警的任務推給了用戶,用戶如何知道哪些站點可以組成陣列,只能依靠直覺,並沒有一個系統有效的方法。但是我們的系統可以作為一個基礎,它也並非沒有實用價值。
我們的帳戶系統秉持我一貫做軟體的經驗,除了代碼有些冗餘,但效果確實有效和完整的。同時,經過測試,確實將我們定義的區域短信全部發送到了我們資料庫的用戶手機中。整個過程沒有發現明顯差錯。
同時,在介面的顯示上,我一改以前傳統按鈕的複雜佈局,直接使用檢測座標的方式來觸發程式功能,節約了不少時間,但這也有一些問題,我們的按鍵沒有效果,比較死板,於是我使用彈窗的形式來中和這樣的負面效果,使得按鍵得到了合理的反饋。
我花費了很多時間在完成頁面的數據連續顯示上,直到最後,我們都沒有獲得一個很好的方案,其中的最大原因,是我對網頁的設計不太熟悉,不能很好的運用ajax和note.js,這方面的知識雖然我有意去學習,然而由於學業緊張,並沒有取得很好的效果,所以最後專題快要結案時,我改變程式設計方向,從B/S架構轉為C/S+B/S架構,完成了很多數據級的任務處理,使得我們的實作內容有實際的運作意義。
我想,對於我來說,最大的問題可能是時間上的,畢竟我們的設想複雜,而又有很多其它學業,沒有給我們反復研究的時間和機會。另外,是心理上的,原地打轉的挫折感會讓我們困惑。但這正是我們要學習的地方,所謂在失敗中進步,在挫折中成長,相信經過這次實作,我們會以更專業的知識,更積極的態度投身到之後的學習中。
<动漫技术宅隐私保护>
2018年12月31日
[報告結束,謝謝。]